11. Kafka消费者分区分配策略
[TOC]前言在本节开始之前,可以先了解一下上一节内容Kafka重平衡机制。一、消费者分区分配策略作用一个consumer group 中有多个consumer,一个 topic 有多个partition,所以必然会涉及到partition 的分配问题,即确定哪个partition 由哪个consumer 来消费。 Kafka 有三种分配策略:RoundRobin(轮询)Range(范围)StickyAssignor同时Kafka也支持自定义分配策略。二、分区分配策略详解2.1 RangeAssignor(默认分配策略)概述范围分区策略:对每个Topic进行独立的分区分配。对于每一个To...
10.【转载】Kafka重平衡机制
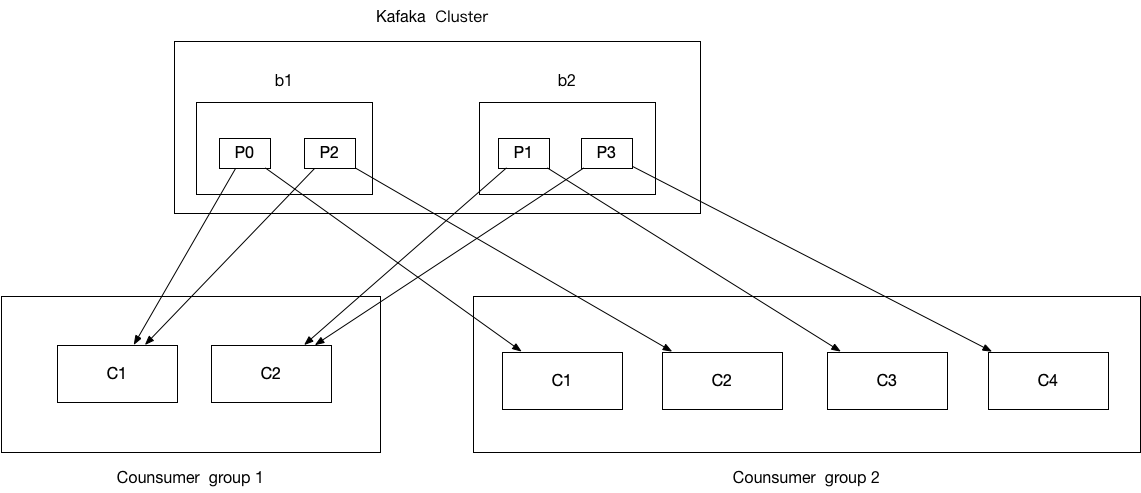
[TOC]前言当集群中有新成员加入,或者某些主题增加了分区之后,消费者是怎么进行重新分配消费的?这里就涉及到重平衡(Rebalance)的概念,下面我就给大家讲解一下什么是 Kafka 重平衡机制,我尽量做到图文并茂通俗易懂。一、重平衡的作用重平衡跟消费组紧密相关,它保证了消费组成员分配分区可以做到公平分配,也是消费组模型的实现,消费组模型如下:从图中可以找到消费组模型的几个概念:同一个消费组,一个分区只能被一个消费者订阅消费,但一个消费者可订阅多个分区,也即是每条消息只会被同一个消费组的某一个消费者消费,确保不会被重复消费;一个分区可被不同消费组订阅,这里有种特殊情况,加入每个消费组只...
09.Kafka消费过程分析
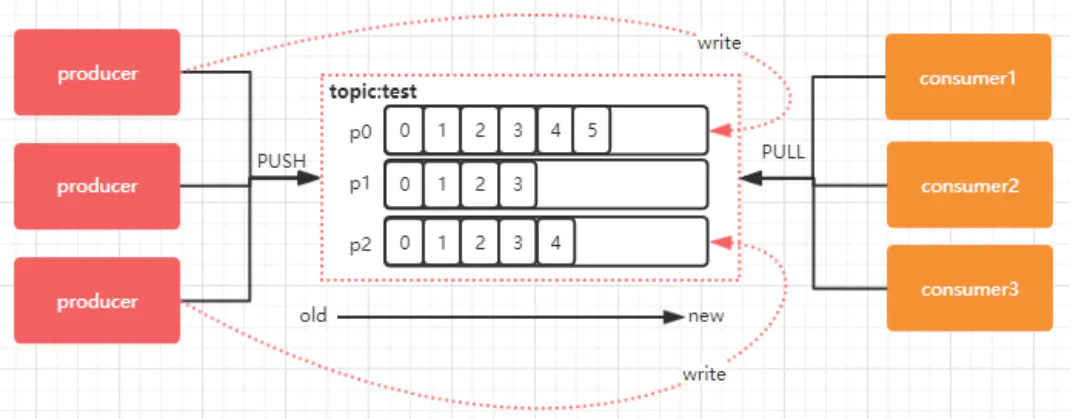
[TOC]一、消费者模型1.1 概念消息由生产者发布到Kafka集群后,会被消费者消费。消息的消费模型有两种:推送模型(Push)拉取模型(Pull)。1.2 推送模型(push)基于推送模型(push)的消息系统,有消息代理记录消费者的消费状态。消息代理在将消息推送到消费者后,标记这条消息已经消费,但这种方式无法很好地保证消费被处理。如果要保证消息被处理,消息代理发送完消息后,要设置状态为“已发送”,只要收到消费者的确认请求后才更新为“已消费”,这就需要代理中记录所有的消费状态,但显然这种方式不可取。缺点push模式很难适应消费速率不同的消费者因为消息发送速率是由broker决定的,p...
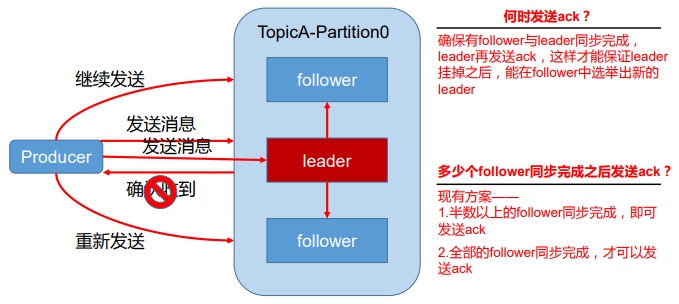
08.Kafka生产者数据可靠性保证
[TOC]一、数据可靠性保证为保证 producer 发送的数据,能可靠的发送到指定的 topic,topic 的每个 partition 收到 producer 发送的数据后,都需要向producer发送 ack(acknowledgement 确认收到),如果 producer 收到 ack,就会进行下一轮的发送,否则重新发送数据。1.1 副本数据同步策略方案优点缺点半数以上完成同步,就发 送 ack延迟低选举新的 leader 时,容忍 n 台 节点的故障,需要 2n+1 个副本全部完成同步,才发送 ack选举新的leader 时,容忍n台节点的故障,需要n+1个副本延迟高Kafk...

中秋随笔
日期:2021年9月21日,阴历八月十五今天是中秋节,没错又是一个人,节日的欢庆也只有透过屏幕才能感受到。本站从2019年10月14日建站,到现在已经快有两年时间,在这两年中也在本站整理和发布了一些技术类文章。也有一些自己的感受,想分享给大家。建站初衷如果有人想问博主的建站初衷是什么,其实回想起来也没那么复杂。一次偶然的机会发现自己名字全拼域名lilinchao.com没有被注册当时一时兴奋就注册了下来,加上对云产品的的好奇,租了一台服务器搭建起了自己的博客。在本站建站之前博主也曾经维护过一个博客,虽然也推送过一些文章,但是除了自己很少再有人能关注到,后来也就不了了之了。为什么要推送系列...
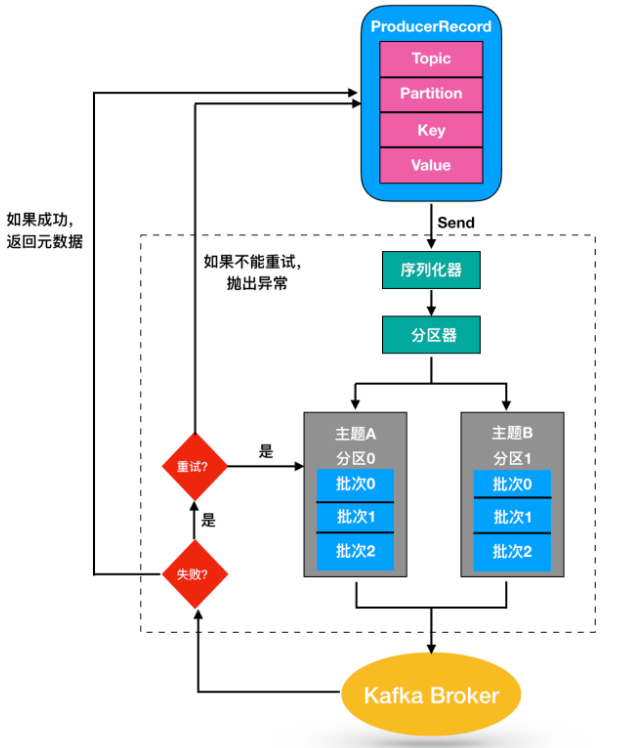
07.Kafka生产者分区策略
[TOC]前言查阅了一些资料和看了许多网上的文章,总觉得没有把Kafka生产者分区策略给讲明白,本篇将围绕以下问题步步深入来对文章进行展开。为什么需要生产者分区策略生产者分区策略有哪些不同分区策略有哪些优点和缺点如何进行自定义分区策略一、生产者发送消息流程说明(1)新建ProducerRecord对象,包含目标主题和要发送的内容,也可以指定键或分区;(2)发送ProducerRecord对象时,生产者要把键和值对象序列化成字节数组,这样它们才能在网络上传输;(3)数据被传给分区器:如果ProducerRecord对象中指定了分区,那么分区器就不会再做任何事情,直接发送到该分区;如果发送时...
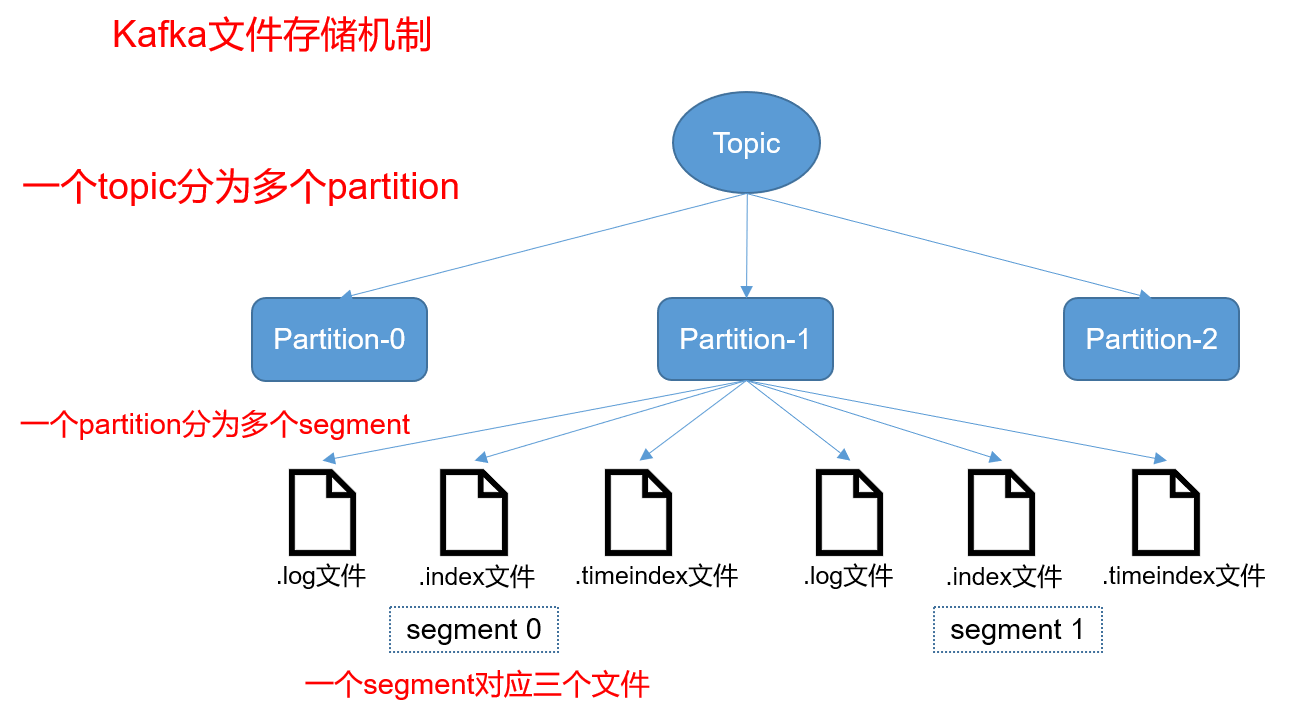
06.Kafka文件存储机制
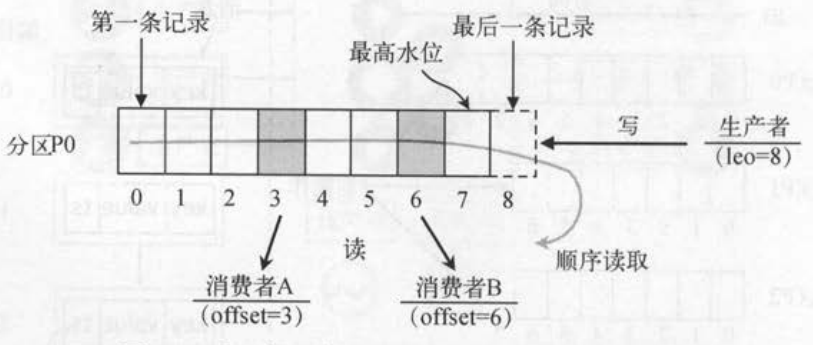
[TOC]一、文件结构说明Kafka 中消息是以 topic 进行分类的,生产者通过 topic 向 Kafka broker 发送消息,消费者通过 topic 读取数据;topic 在物理层面又能以 partition 为分组, 一个 topic 可以分成若干个 partition;partition 还可以细分为 segment,一个 partition 物理上由多个 segment 组成。二、Partition分区2.1 查看分区结构在config/server.properties配置文件下可以查看到Kafka数据存放目录[root@hadoopserver config]# p...
08.HDFS文件目录介绍
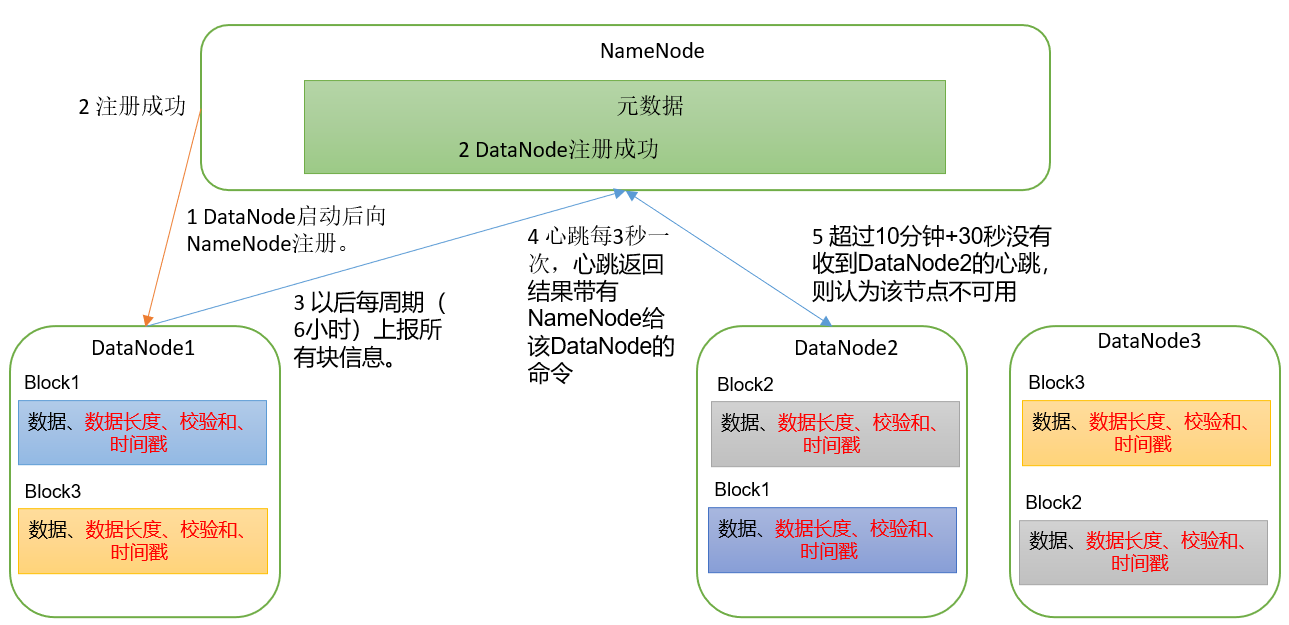
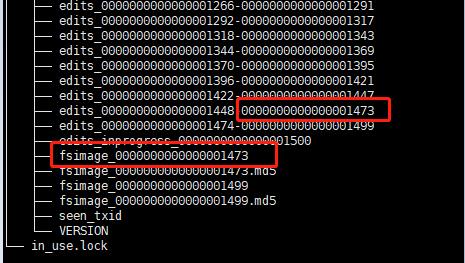
[TOC]前言HDFS metadata以树状结构存储整个HDFS上的文件和目录,以及相应的权限、配额和副本因子(replication factor)等。一、NameNode1.1 NameNode目录结构进入到hadoop-2.8.5/tmp/dfs目录下执行如下命令可查看NameNode目录结构[root@hadoopserver dfs]# pwd /usr/local/hadoop-2.8.5/tmp/dfs [root@hadoopserver dfs]# tree name name ├── current │ ├── edits_0000000000000000001...
07.HDFS之Fsimage和Edits详解
[TOC]前言之前在文章HDFS之NameNode和SecondaryNameNode中简单介绍过Fsimage和EditLog,但是总结的还是有很多漏洞,小编又查阅一些资料在此进行一下补充。一、NameNode元数据1.1 概述NameNode 的所有操作及整个集群的状态都存储在metadata(元数据)中,metadata通过 Fsimage 和 Eidts 文件保存。metadata作用是在集群启动时将集群的状态恢复到关闭前的状态。也就是 Hadoop集群因为各种原因需要重新启动,元数据能保证集群启动之后的状态和上次停止前的状态一致。1.2 数据恢复过程第一次启动 NameNode...