李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
06.Kafka文件存储机制
Leefs
2021-09-20 PM
1253℃
0条
[TOC] ### 一、文件结构 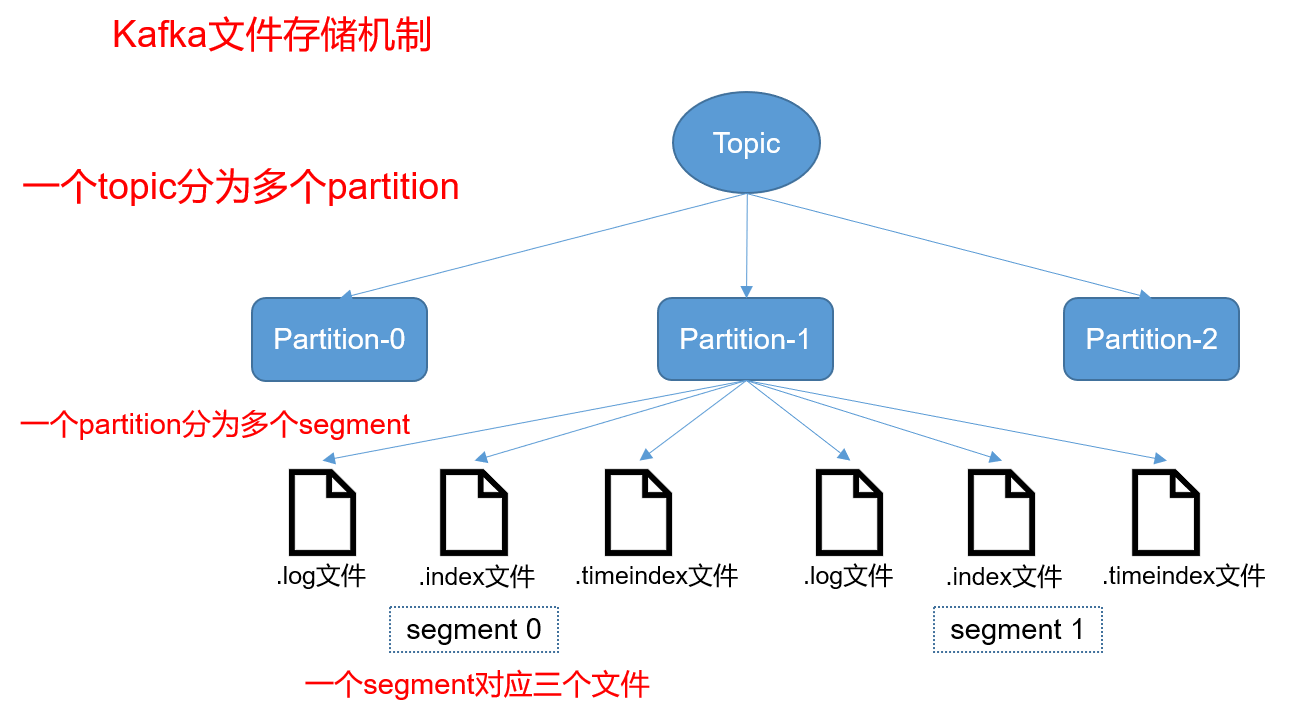 **说明** + Kafka 中消息是以 topic 进行分类的,生产者通过 topic 向 Kafka broker 发送消息,消费者通过 topic 读取数据; + topic 在物理层面又能以 partition 为分组, 一个 topic 可以分成若干个 partition; + partition 还可以细分为 segment,一个 partition 物理上由多个 segment 组成。 ### 二、Partition分区 #### 2.1 查看分区结构 在`config/server.properties`配置文件下可以查看到Kafka数据存放目录 ```bash [root@hadoopserver config]# pwd /usr/local/kafka_2.12-2.8.0/config [root@hadoopserver config]# vim server.properties log.dirs=/usr/local/kafka_2.12-2.8.0/data ``` 进入分区目录查看分区文件 ``` [root@hadoopserver data]# pwd /usr/local/kafka_2.12-2.8.0/data [root@hadoopserver data]# ls -la ```  **说明** partiton命名规则为`topic名称+有序序号`,第一个partiton序号从0开始,序号最大值为partitions数量减1。 #### 2.2 分区的作用 为了性能考虑,如果不分区每个topic的消息只存在一个broker上,那么所有的消费者都是从这个broker上消费消息,那么单节点的broker成为性能的瓶颈,如果有分区的话生产者发过来的消息分别存储在各个broker不同的partition上,这样消费者可以并行的从不同的broker不同的partition上读消息,实现了水平扩展。 #### 2.3 分区下数据文件 查看demo-0分区目录结构 ```bash [root@hadoopserver data]# tree demo-0/ demo-0/ ├── 00000000000000000001.index ├── 00000000000000000001.log ├── 00000000000000000001.timeindex ├── 00000000000000001018.index ├── 00000000000000001018.log ├── 00000000000000001018.timeindex ├── 00000000000000002042.index ├── 00000000000000002042.log ├── 00000000000000002042.timeindex ``` 每个分区下保存了很多文件,而概念上我们把他叫segment,即每个分区都是又多个segment构成的。 ### 三、Segment存储 #### 3.1 Segment组成和命名 从上方数据我们可以看到,segment是由以下部分组成: + **index**:索引文件 + **log**:数据文件 + **timeindex**:时间索引文件 **segment文件命名规则:**partion全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值。 数值最大为64位long大小,20位数字字符长度,没有数字用0填充。 **命名规则的好处:方便进行二分查找,快速定位到数据文件** #### 3.2 Segment作用 如果不引入segment,那么一个partition只对应一个文件(log),随着消息的不断发送这个文件不断增大,由于kafka的消息不会做更新操作都是顺序写入的,如果做消息清理的时候只能对文件的前面部分进行删除,不符合kafka顺序写入的设计,如果多个segment的话那就比较方便了,直接删除整个文件即可保证了每个segment的顺序写入。 #### 3.3 index和log文件物理结构  **说明** 上图的左半部分是索引文件,里面存储的是一对一对的key-value,右半部分是索引文件所对应的数据文件。 + **索引文件key**:消息在数据文件(对应的log文件)中的编号,比如“1,3,6,8……”,分别表示在log文件中的第1条消息、第3条消息、第6条消息、第8条消息。 + **索引文件value**:表示消息的物理偏移地址(位置) **优点** index文件中并没有为数据文件中的每条消息都建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。 **缺点** 没有建立索引的Message也不能一次定位到其在数据文件的位置,从而需要做一次顺序扫描。 #### 3.4 Message物理结构 从上图右半部分的segment数据文件可以看到,log数据文件中并不是直接存储数据,而是通过许多的message组成,message包含了实际的消息数据,下面将对Message物理结构进行详细说明。  | 关键字 | 解释说明 | | ------------------- | ------------------------------------------------------------ | | 8 byte offset | 在parition(分区)内的每条消息都有一个有序的id号,这个id号被称为偏移(offset),它可以唯一确定每条消息在parition(分区)内的位置。即offset表示partiion的第多少message | | 4 byte message size | message大小 | | 4 byte CRC32 | 用crc32校验message | | 1 byte “magic” | 表示本次发布Kafka服务程序协议版本号 | | 1 byte “attributes” | 表示为独立版本、或标识压缩类型、或编码类型 | | 4 byte key length | 表示key的长度,当key为-1时,K byte key字段不填 | | K byte key | 可选 | | value bytes payload | 表示实际消息数据 | ### 四、消费者如何通过offset查找message 假如我们想要读取offset=1066的message,需要通过下面2个步骤查找: **步骤一:查找segment file** 00000000000000000000.index表示最开始的文件,起始偏移量(offset)为0.第二个文件00000000000000001018.index的消息量起始偏移量为1019 = 1018 + 1.同样,第三个文件00000000000000002042.index的起始偏移量为2043=2042 + 1,其他后续文件依次类推,以起始偏移量命名并排序这些文件,只要根据offset **二分查找**文件列表,就可以快速定位到具体文件。 当offset=1066时定位到00000000000000001018.index|log。 **步骤二:通过segment file查找message** 通过第一步定位到segment file,当offset=1066时,依次定位到00000000000000001018.index的元数据物理位置和00000000000000001018.log的物理偏移地址,此时我们只能拿到1065的物理偏移地址,然后再通过00000000000000368769.log顺序查找直到offset=1066为止。每个message都有固定的格式很容易判断是否是下一条消息。  *附参考文章链接:* *https://segmentfault.com/a/1190000021824942?utm_source=tag-newest* *https://www.cnblogs.com/yitianyouyitian/p/10287293.html*
标签:
Kafka
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://www.lilinchao.com/archives/1510.html
上一篇
08.HDFS文件目录介绍
下一篇
07.Kafka生产者分区策略
取消回复
评论啦~
提交评论
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
标签云
Spark Streaming
Sentinel
Kibana
Scala
Nacos
Spark
Python
数据结构
nginx
并发编程
gorm
线程池
Yarn
JavaWeb
人工智能
Ubuntu
Flume
Git
Spark Core
JVM
JavaWEB项目搭建
Netty
数学
高并发
Typora
Zookeeper
链表
GET和POST
FileBeat
递归
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞