
SparkSQL案例实操(四)
[TOC]一、需求统计有过连续3天以上销售的店铺,并计算销售额结果示例+-----+----------+----------+-----+-----------+ | sid|begin_date| end_date|times|total_sales| +-----+----------+----------+-----+-----------+ |shop1|2019-02-10|2019-02-13| 4| 1900| +-----+----------+----------+-----+-----------+二、数据准备order.csvsid,data...
SparkSQL案例实操(三)
[TOC]一、需求统计连续登录三天及以上的用户这个问题可以扩展到很多相似的问题:连续几个月充值会员、连续天数有商品卖出、连续打滴滴、连续逾期。示例uidtimesstart_dateend_dateguid0142018-03-042018-03-07guid0232018-03-012018-03-03二、数据准备v_user_login.csvuid,datatime guid01,2018-02-28 guid01,2018-03-01 guid01,2018-03-02 guid01,2018-03-04 guid01,2018-03-05 guid01,2018-03-06 g...
SparkSQL案例实操(二)
[TOC]一、需求1.1 需求简介各区域热门商品 Top3这里的热门商品是从点击量的维度来看的,计算各个区域前三大热门商品备注上每个商品在主要城市中的分布比例超过两个城市用其他显示示例地区商品名称点击次数城市备注华北商品 A100000北京 21.2%,天津 13.2%,其他 65.6%华北商品 P80200北京 63.0%,太原 10%,其他 27.0%华北商品 M40000北京 63.0%,太原 10%,其他 27.0%东北商品 J92000大连 28%,辽宁 17.0%,其他 55.0%1.2 需求分析查询出来所有的点击记录,并与 city_info 表连接,得到每个城市所在的地区...
SparkSQL案例实操(一)
[TOC]一、需求统计每个用户的累计访问次数要求使用SQL统计出每个用户的累积访问次数,如下表所示:用户id月份小计累积u012021-011111u012021-021223u022021-011212u032021-0188u042021-0133说明:累计访问次数按照月份进行排序,根据每个用户逐月进行累加二、数据准备user_access_count.csv文件userid,visitdate,visitcount u01,2021/1/21,5 u02,2021/1/23,6 u03,2021/1/22,8 u04,2021/1/20,3 u01,2021/1/23,6 u01,...
SparkCore之广播变量
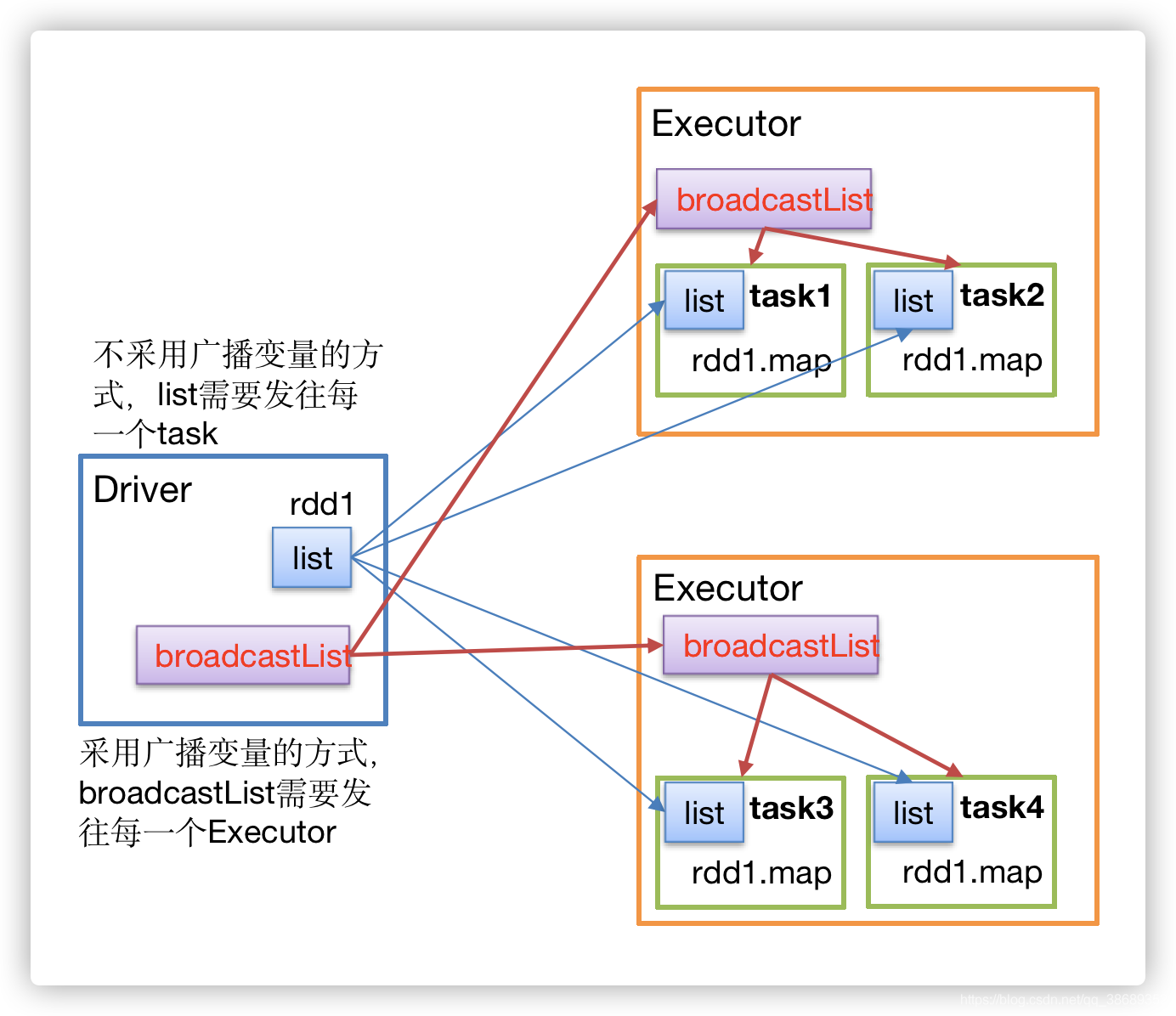
[TOC]一、定义广播变量:分布式共享只读变量二、作用在多个并行操作中(Executor)使用同一个变量,Spark默认会为每个任务(Task)分别发送,这样如果共享比较大的对象,会占用很大工作节点的内存。广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个或多个Spark操作使用。比如,如果你的应用需要向所有节点发送一个较大的只读查询表,甚至是机器学习算法中的一个很大的特征向量,广播变量用起来都很顺手。三、原理说明说明如果不采用广播变量的方式,list需要将数据发送给每一个task采用广播变量的方式,只需要将数据发送到每一个Executor,其他任务在执行的时候...
SparkCore之累加器
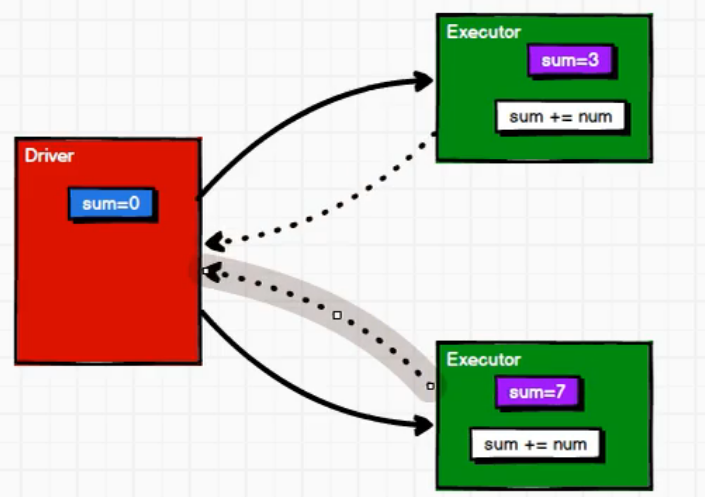
[TOC]前言本篇将先从一个案例入手,对Driver端和Executer端执行过程进行一个简单了解,在深入讲解累加器。一、累加操作案例案例需求将1,2,3,4进行累加求和操作代码import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * @author lilinchao * @date 2021/11/9 * @description 1.0 **/ object Spark_WordCount { def main(args: Array[St...

Spark Core案例实操(十)
[TOC]一、需求影评分析:按照年份进行分组。计算每部电影的平均评分,平均评分保留小数点后一位,并按评分大小进行排序。评分一样,按照电影名排序。相同年份的输出到一个文件中。结果展示形式(年份,电影id,电影名字,平均评分)要求:尝试使用自定义分区、自定义排序和缓冲。二、数据说明说明:以::对数据进行分隔movies.dat电影列表文件第一列:电影ID第二列:电影名称第三列:电影类型ratings.dat用户评分文件第一列:用户ID第二列:电影ID第三列:评分第四列:评分时间戳三、实现代码3.1 思路1. 先处理评分数据,计算出电影id、平均评分 2. 再处理电影数据,提取出电影id、电影...
Spark Core案例实操(九)
一、需求分析CDN日志统计出访问PV、UV、IP地址:计算独立ip数统计每个视频独立ip数统计一天中每个小时的流量(统计每天24小时中每个小时的流量)说明PV(page view): 页面浏览量,页面点击率;通常衡量一个网站或者新闻频道一条新闻的指标;UV(unique visitor ): 指访问某个站点或者点击某条新闻的不同的ip的人数二、数据说明100.79.121.48 HIT 33 [15/Feb/2017:00:00:46 +0800] "GET http://cdn.v.abc.com.cn/videojs/video.js HTTP/1.1" 200 ...

Spark Core案例实操(八)
[TOC]一、需求基站停留时间TOPN:根据用户产生的日志信息,分析在哪个基站停留的时间最长在一定范围内,求所有用户经过的所有基站所停留时间最长的TOP2二、数据说明19735E1C66.log:存储的日志信息第一列:手机号码第二列:时间戳第三列:基站ID第四列:连接状态(1连接,0断开)lac_info.txt:存储基站信息第一列:基站id第二列:经度第三列:纬度三、实现3.1 实现步骤1. 获取用户产生的日志信息并切分 2. 用户在基站停留的总时长 3. 获取基站的基本信息 4. 把经纬度的信息join到用户数据中 5. 求除用户在某些基站停留时间的top23.2 代码实现packa...

Spark Core案例实操(七)
[TOC]一、需求根据访问日志的ip地址做如下操作:计算出访问者的归属地按照省份,计算出访问次数将计算好的结果输出到控制台二、数据分析access.log日志文件第一列:ID第二列:访问者IP第三列:访问网址后面没用到就不详细介绍了ip.txtIP规则文件第一列和第二列:开始IP和结束IP(一个范围)第三列和第四列:开始IP和结束IP十进制第五、六、七、八列:对应地区分别是洲、国家、省/直辖市、市/区第九列:运营商名称三、实现3.1 步骤1.整理数据,切分出ip字段,然后将ip地址转换成十进制 2.加载规则,整理规则,取出有用的字段,然后将数据缓存到内存中 3.将访问log与ip规则进行...