李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
05.数仓建设之实时数仓建设核心
Leefs
2022-09-26 AM
688℃
0条
[TOC] ### 一、实时计算初期 虽然实时计算在最近几年才火起来,但是在早期也有部分公司有实时计算的需求,但是数据量比较少,所以在实时方面形成不了完整的体系,基本所有的开发都是具体问题具体分析,来一个需求做一个,基本不考虑它们之间的关系,开发形式如下: 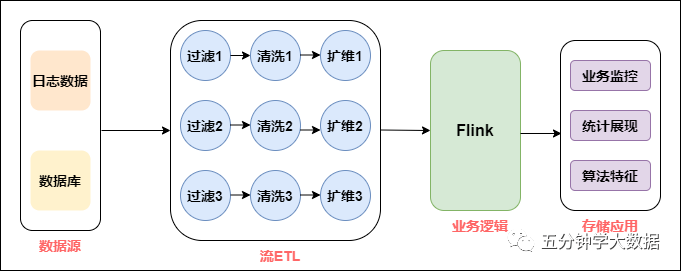 如上图所示,拿到数据源后,会经过数据清洗,扩维,通过Flink进行业务逻辑处理,最后直接进行业务输出。把这个环节拆开来看,数据源端会重复引用相同的数据源,后面进行清洗、过滤、扩维等操作,都要重复做一遍,唯一不同的是业务的代码逻辑是不一样的。 随着产品和业务人员对实时数据需求的不断增多,这种开发模式出现的问题越来越多: - 数据指标越来越多,“烟囱式”的开发导致代码耦合问题严重。 - 需求越来越多,有的需要明细数据,有的需要 OLAP 分析。单一的开发模式难以应付多种需求。 - 每个需求都要申请资源,导致资源成本急速膨胀,资源不能节约有效利用。 - 缺少完善的监控系统,无法在对业务产生影响之前发现并修复问题。 大家看实时数仓的发展和出现的问题,和离线数仓非常类似,后期数据量大了之后产生了各种问题,离线数仓当时是怎么解决的?离线数仓通过分层架构使数据解耦,多个业务可以共用数据,实时数仓是否也可以用分层架构呢?当然是可以的,但是细节上和离线的分层还是有一些不同,稍后会讲到。 ### 二、实时数仓建设 从方法论来讲,实时和离线是非常相似的,离线数仓早期的时候也是具体问题具体分析,当数据规模涨到一定量的时候才会考虑如何治理。分层是一种非常有效的数据治理方式,所以在实时数仓如何进行管理的问题上,首先考虑的也是分层的处理逻辑。 实时数仓的架构如下图:  从上图中我们具体分析下每层的作用: - **数据源:**在数据源的层面,离线和实时在数据源是一致的,主要分为日志类和业务类,日志类又包括用户日志,埋点日志以及服务器日志等。 - **实时明细层:**在明细层,为了解决重复建设的问题,要进行统一构建,利用离线数仓的模式,建设统一的基础明细数据层,按照主题进行管理,明细层的目的是给下游提供直接可用的数据,因此要对基础层进行统一的加工,比如清洗、过滤、扩维等。 - **汇总层:**汇总层通过Flink的简洁算子直接可以算出结果,并且形成汇总指标池,所有的指标都统一在汇总层加工,所有人按照统一的规范管理建设,形成可复用的汇总结果。 我们可以看出,实时数仓和离线数仓的分层非常类似,比如 数据源层,明细层,汇总层,乃至应用层,他们命名的模式可能都是一样的。但仔细比较不难发现,两者有很多区别: - 与离线数仓相比,实时数仓的层次更少一些: + 从目前建设离线数仓的经验来看,数仓的数据明细层内容会非常丰富,处理明细数据外一般还会包含轻度汇总层的概念,另外离线数仓中应用层数据在数仓内部,**但实时数仓中,app 应用层数据已经落入应用系统的存储介质中,可以把该层与数仓的表分离。** + 应用层少建设的好处:**实时处理数据的时候,每建一个层次,数据必然会产生一定的延迟** + 汇总层少建的好处:在汇总统计的时候,往往为了容忍一部分数据的延迟,可能会人为的制造一些延迟来保证数据的准确。举例,在统计跨天相关的订单事件中的数据时,可能会等到 00:00:05 或者 00:00:10 再统计,确保 00:00 前的数据已经全部接收到位了,再进行统计。所以,汇总层的层次太多的话,就会更大的加重人为造成的数据延迟。 - 与离线数仓相比,实时数仓的数据源存储不同: + 在建设离线数仓的时候,**基本整个离线数仓都是建立在 Hive 表之上。**但是,在建设实时数仓的时候,同一份表,会使用不同的方式进行存储。比如常见的情况下,**明细数据或者汇总数据都会存在 Kafka 里面,但是像城市、渠道等维度信息需要借助 Hbase,MySQL 或者其他 KV 存储等数据库来进行存储。** ### 三、Lambda架构的实时数仓 下图是基于 Flink 和 Kafka 的 Lambda 架构的具体实践,上层是实时计算,下层是离线计算,横向是按计算引擎来分,纵向是按实时数仓来区分:  Lambda架构是比较经典的架构,以前实时的场景不是很多,以离线为主,当附加了实时场景后,由于离线和实时的时效性不同,导致技术生态是不一样的。Lambda架构相当于附加了一条实时生产链路,在应用层面进行一个整合,双路生产,各自独立。这在业务应用中也是顺理成章采用的一种方式。 双路生产会存在一些问题,比如加工逻辑double,开发运维也会double,资源同样会变成两个资源链路。因为存在以上问题,所以又演进了一个Kappa架构。 ### 四、Kappa架构的实时数仓 Kappa架构相当于去掉了离线计算部分的Lambda架构,具体如下图所示:  Kappa架构从架构设计来讲比较简单,生产统一,一套逻辑同时生产离线和实时。但是在实际应用场景有比较大的局限性,因为实时数据的同一份表,会使用不同的方式进行存储,这就导致关联时需要跨数据源,操作数据有很大局限性,所以在业内直接用Kappa架构生产落地的案例不多见,且场景比较单一。 关于 Kappa 架构,熟悉实时数仓生产的同学,可能会有一个疑问。因为我们经常会面临业务变更,所以很多业务逻辑是需要去迭代的。之前产出的一些数据,如果口径变更了,就需要重算,甚至重刷历史数据。对于实时数仓来说,怎么去解决数据重算问题? Kappa 架构在这一块的思路是:首先要准备好一个能够存储历史数据的消息队列,比如 Kafka,并且这个消息队列是可以支持你从某个历史的节点重新开始消费的。接着需要新起一个任务,从原来比较早的一个时间节点去消费 Kafka 上的数据,然后当这个新的任务运行的进度已经能够和现在的正在跑的任务齐平的时候,你就可以把现在任务的下游切换到新的任务上面,旧的任务就可以停掉,并且原来产出的结果表也可以被删掉。 ### 五、流批结合的实时数仓 随着实时 OLAP 技术的发展,目前开源的OLAP引擎在性能,易用等方面有了很大的提升,如Doris、Presto等,加上数据湖技术的迅速发展,使得流批结合的方式变得简单。 如下图是流批结合的实时数仓:  数据从日志统一采集到消息队列,再到实时数仓,作为基础数据流的建设是统一的。之后对于日志类实时特征,实时大屏类应用走实时流计算。对于Binlog类业务分析走实时OLAP批处理。 我们看到流批结合的方式与上面几种架构的存储方式发生了变化,由Kafka换成了Iceberg,Iceberg是介于上层计算引擎和底层存储格式之间的一个中间层,我们可以把它定义成一种“数据组织格式”,底层存储还是HDFS,那么为什么加了中间层,就对流批结合处理的比较好了呢?Iceberg的ACID能力可以简化整个流水线的设计,降低整个流水线的延迟,并且所具有的修改、删除能力能够有效地降低开销,提升效率。Iceberg可以有效支持批处理的高吞吐数据扫描和流计算按分区粒度并发实时处理。 *原文链接地址* *https://mp.weixin.qq.com/s/gCEXqGKkXrLvEC1zpUOoNQ*
标签:
DataWarehouse
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://www.lilinchao.com/archives/2394.html
上一篇
04.数仓建设之实时计算
下一篇
06.数仓建设之基于Flink SQL从0到1构建一个实时数仓
取消回复
评论啦~
提交评论
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
标签云
Map
随笔
ClickHouse
FastDFS
LeetCode刷题
Scala
JVM
栈
数学
Beego
Nacos
散列
Livy
Flink
Elasticsearch
Hadoop
VUE
稀疏数组
排序
JavaSE
DataWarehouse
国产数据库改造
Linux
查找
Quartz
Azkaban
机器学习
Docker
Hbase
队列
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞