李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
Java
正文
18.NIO之零拷贝
Leefs
2022-06-05 AM
719℃
0条
[TOC] ### 一、传统IO问题 传统的 IO 将一个文件通过 socket 写出 ```java File f = new File("helloword/data.txt"); RandomAccessFile file = new RandomAccessFile(file, "r"); byte[] buf = new byte[(int)f.length()]; file.read(buf); Socket socket = ...; socket.getOutputStream().write(buf); ``` 内部工作流程是这样的: 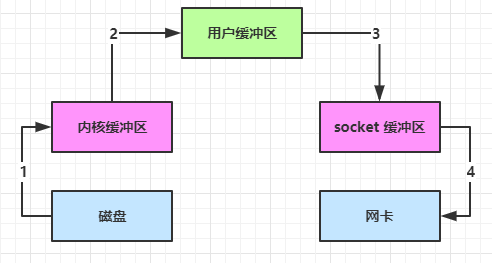 1. java 本身并不具备 IO 读写能力,因此 read 方法调用后,要从 java 程序的**用户态**切换至**内核态**,去调用操作系统(Kernel)的读能力,将数据读入**内核缓冲区**。这期间用户线程阻塞,操作系统使用 DMA(Direct Memory Access)来实现文件读,其间也不会使用 cpu; 2. 从**内核态**切换回**用户态**,将数据从**内核缓冲区**读入**用户缓冲区**(即 byte[] buf),这期间 cpu 会参与拷贝,无法利用 DMA; 3. 调用 write 方法,这时将数据从**用户缓冲区**(byte[] buf)写入 **socket 缓冲区**,cpu 会参与拷贝; 4. 接下来要向网卡写数据,这项能力 java 又不具备,因此又得从**用户态**切换至**内核态**,调用操作系统的写能力,使用 DMA 将 **socket 缓冲区**的数据写入网卡,不会使用 cpu。 可以看到中间环节较多,java 的 IO 实际不是物理设备级别的读写,而是缓存的复制,底层的真正读写是操作系统来完成的 * 用户态与内核态的切换发生了 3 次,这个操作比较重量级 * 数据拷贝了共 4 次 ### 二、NIO 优化 #### 2.1 优化一 通过 DirectByteBuf * ByteBuffer.allocate(10) HeapByteBuffer 使用的还是 java 内存 * ByteBuffer.allocateDirect(10) DirectByteBuffer 使用的是操作系统内存  大部分步骤与优化前相同,不再赘述。唯有一点:java 可以使用 DirectByteBuf 将堆外内存映射到 jvm 内存中来直接访问使用 * 这块内存不受 jvm 垃圾回收的影响,因此内存地址固定,有助于 IO 读写 * java 中的 DirectByteBuf 对象仅维护了此内存的虚引用,内存回收分成两步 * DirectByteBuf 对象被垃圾回收,将虚引用加入引用队列 * 通过专门线程访问引用队列,根据虚引用释放堆外内存 * 减少了一次数据拷贝,用户态与内核态的切换次数没有减少 #### 2.2 优化二 进一步优化(底层采用了 linux 2.1 后提供的 sendFile 方法),java 中对应着两个 channel 调用 transferTo/transferFrom 方法拷贝数据  1. java 调用 transferTo 方法后,要从 java 程序的**用户态**切换至**内核态**,使用 DMA将数据读入**内核缓冲区**,不会使用 cpu 2. 数据从**内核缓冲区**传输到 **socket 缓冲区**,cpu 会参与拷贝 3. 最后使用 DMA 将 **socket 缓冲区**的数据写入网卡,不会使用 cpu 可以看到 * 只发生了一次用户态与内核态的切换 * 数据拷贝了 3 次 #### 2.3 优化三 进一步优化(linux 2.4)  1. java 调用 transferTo 方法后,要从 java 程序的**用户态**切换至**内核态**,使用 DMA将数据读入**内核缓冲区**,不会使用 cpu 2. 只会将一些 offset 和 length 信息拷入 **socket 缓冲区**,几乎无消耗 3. 使用 DMA 将 **内核缓冲区**的数据写入网卡,不会使用 cpu 整个过程仅只发生了一次用户态与内核态的切换,数据拷贝了 2 次。 ### 总结 所谓的【零拷贝】,并不是真正无拷贝,而是在不会拷贝重复数据到 jvm 内存中,零拷贝的优点有 * 更少的用户态与内核态的切换 * 不利用 cpu 计算,减少 cpu 缓存伪共享 * 零拷贝适合小文件传输 *附参考原文:* *《黑马程序员Netty教程》*
标签:
Netty
,
NIO
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://www.lilinchao.com/archives/2127.html
上一篇
17.NIO之IO模型
下一篇
01.Netty概述
取消回复
评论啦~
提交评论
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
标签云
ClickHouse
稀疏数组
排序
Hive
Flink
Scala
JavaWEB项目搭建
Map
并发线程
Elastisearch
Docker
设计模式
Thymeleaf
序列化和反序列化
MyBatis
Shiro
BurpSuite
Java编程思想
微服务
RSA加解密
ajax
JVM
Redis
随笔
Jenkins
FastDFS
正则表达式
Jquery
FileBeat
Typora
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞