李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
08.ClickHouse副本和分片介绍
Leefs
2022-05-03 PM
1612℃
0条
# 08.ClickHouse副本和分片介绍 ### 一、概述 集群是副本和分片的基础,它将ClickHouse的服务拓扑由单节点延伸到多个节点,但它并不像Hadoop生态的某些系统那样,要求所有节点组成一个单一的大集群。ClickHouse的集群配置非常灵活,用户既可以将所有节点组成一个单一集群,也可以按照业务的诉求,把节点划分为多个小的集群。在每个小的集群区域之间,它们的节点、分区和副本数量可以各不相同,如图所示。 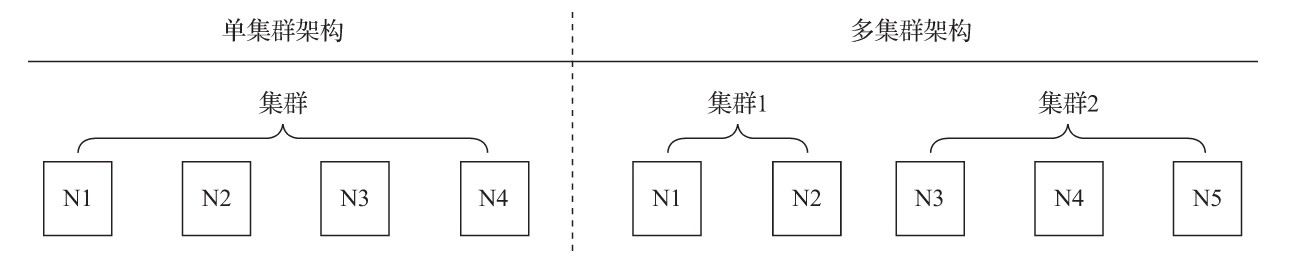 从作用来看,ClickHouse集群的工作更多是针对逻辑层面的。集群定义了多个节点的拓扑关系,这些节点在后续服务过程中可能会协同工作,而执行层面的具体工作则交给了副本和分片来执行。 副本和分片这对双胞胎兄弟,有时候看起来泾渭分明,有时候又让人分辨不清。 这里有两种区分的方法。 一种是从数据层面区分,假设ClickHouse的N个节点组成了一个集群,在集群的各个节点上,都有一张结构相同的数据表Y。如果N1的Y和N2的Y中的数据完全不同,则N1和N2互为分片;如果它们的数据完全相同,则它们互为副本。换言之,**分片之间的数据是不同的,而副本之间的数据是完全相同的**。所以抛开表引擎的不同,单纯从数据层面来看,副本和分片有时候只有一线之隔。 另一种是从功能作用层面区分,**使用副本的主要目的是防止数据丢失,增加数据存储的冗余;而使用分片的主要目的是实现数据的水平切分**,如图所示。  ### 二、数据副本 #### 概述 不知大家是否还记得,在介绍`MergeTree`的时候,曾经讲过它的命名规则。如果在`*MergeTree`的前面增加`Replicated`的前缀,则能够组合成一个新的变种引擎,即`Replicated-MergeTree`复制表。  换言之,只有使用了`ReplicatedMergeTree`复制表系列引擎,才能应用副本的能力。或者用一种更为直接的方式理解,即使用`ReplicatedMergeTree`的数据表就是副本。 `ReplicatedMergeTree`是`MergeTree`的派生引擎,它在`MergeTree`的基础上加入了分布式协同的能力。  在MergeTree中,一个数据分区由开始创建到全部完成,会历经两类存储区域。 **(1)内存:数据首先会被写入内存缓冲区。** **(2)本地磁盘:数据接着会被写入tmp临时目录分区,待全部完成后再将临时目录重命名为正式分区。** ReplicatedMergeTree在上述基础之上增加了ZooKeeper的部分,它会进一步在ZooKeeper内创建一系列的监听节点,并以此实现多个实例之间的通信。在整个通信过程中,ZooKeeper并不会涉及表数据的传输。 #### 副本的特点 **作为数据副本的主要实现载体,ReplicatedMergeTree 在设计上有一些显著特点。** + **依赖 ZooKeeper:在执行 INSERT 和 ALTER 查询的时候,ReplicatedMergeTree 需要借助 ZooKeeper 的分布式协同能力,来实现多个副本之间的同步。但是在查询副本的时候,并不需要使用 ZooKeeper。** + **表级别的副本:副本是在表级别定义的,所以每张表的副本配置都可以按照它的实际需求进行个性化定义,包括副本的数量,以及副本在集群内的分布位置。** + **多主架构(Multi Master):可以在任意一个副本上执行 INSERT 和 ALTER 查询,它们的效果是相同的,这些操作会借助 ZooKeeper 的协同能力被分发至每个副本以本地形式执行。** + **Block 数据块:在执行 INSERT 命令写入数据时,会依据 max_insert_block_size 的大小(默认 1048576 行)将数据切分成若干个 Block 数据块。因此 Block 数据块是数据写入的基本单元,并且具有写入的原子性和唯一性。** + **原子性:在数据写入时,一个 Block 数据块内的数据要么全部写入成功,要么全部写入失败。** + **唯一性:在写入一个 Block 数据块的时候,会按照当前 Block 数据块的数据顺序、数据行和数据大小等指标,计算 Hash 信息摘要并记录。在此之后,如果某个待写入的 Block 数据块与先前已被写入的 Block 数据块拥有相同的 Hash 摘要(Block 数据块内数据顺序、数据大小和数据行均相同),则该 Block 数据块会被忽略。这项设置可以预防由异常原因引起的 Block 数据块重复写入的问题。** #### 副本的定义形式 正如前文所言,使用副本的好处甚多。首先,由于增加了数据的存储冗余,所以降低了数据丢失的风险;其次,由于副本采用了多主架构,所以每个副本实例都可以作为数据读、写的入口,这无疑分摊了节点的负载。 **在使用副本时,不需要依赖任何集群的配置,ReplicatedMergeTree 结合 ZooKeeper 就能完成全部工作。** **ReplicatedMergeTree 的定义方式如下:** ```sql ENGINE = ReplicatedMergeTree('zk_path', 'replica_name') ``` 在上述配置项中,有 `zk_path` 和 `replica_name` 两项,首先介绍 `zk_path` 的作用。 `zk_path` 用于指定在 ZooKeeper 中创建的数据表的路径,路径名称是自定义的,并没有固定规则,用户可以设置成自己希望的任何路径。即便如此,ClickHouse 还是提供了一些约定俗成的配置模板以供参考,例如: ```sql /clickhouse/tables/{shard}/table_name ``` **其中:** + **clickhouse/tables**: 是约定俗成的路径固定前缀,表示存放数据表的根路径。 + **{shard}**: 表示分片编号,通常用数值替代,例如 01、02、03,一张数据表可以有多个分片,而每个分片都拥有自己的副本。 + **table_name**: 表示数据表的名称,为了方便维护,通常与物理表的名字相同(虽然 ClickHouse 并不要求路径中的表名称和物理表名必须一致);而 replica_name 的作用是定义在 ZooKeeper 中创建的副本名称,该名称是区分不同副本实例的唯一标识。一种约定俗成的方式是使用所在服务器的域名称。 **对于 zk_path 而言,同一张数据表的同一个分片的不同副本,应该定义相同的路径;而对于 replica_name 而言,同一张数据表的同一个分片的不同副本,应该定义不同的名称。**读起来很拗口,我们举个栗子说明一下。 + **1 个分片、1 个副本的情形:** ```sql -- zk_path 相同,replica_name 不同 ReplicatedMergeTree('/clickhouse/tables/01/test_1', '192.168.0.1') ReplicatedMergeTree('/clickhouse/tables/01/test_1', '192.168.0.2') ``` + **多个分片、1 个副本的情形:** ```sql -- 分片1(2 分片、1 副本),zk_path 相同,其中 shard = 01,replica_name 不同 ReplicatedMergeTree('/clickhouse/tables/01/test_1', '192.168.0.1') ReplicatedMergeTree('/clickhouse/tables/01/test_1', '192.168.0.2') -- 分片2(2 分片、1 副本),zk_path 相同,其中 shard = 02,replica_name 不同 ReplicatedMergeTree('/clickhouse/tables/02/test_1', '192.168.0.3') ReplicatedMergeTree('/clickhouse/tables/02/test_1', '192.168.0.4') ``` 首先是 zk_path,无论一张表有多少个分片、多少个副本,它们终归属于同一张表,所以 zk_path 的最后一部分、也就是表名称是不变的,这里始终是 test_1。但问题是多个分片之间要如何区分呢?所以此时就依赖于 {shard},/clickhouse/tables/01/test_1 表示 test_1 的第 1 个分片,/clickhouse/tables/02/test_1 表示 test_1 的第 2 个分片,第 3、4、5..... 个分片依次类推,至于其它的表也是同理。 而一个分片不管有多少个副本,这些副本终归都属于同一个分片、同一张表。所以同一张数据表的同一个分片的不同副本,应该定义相同的路径;例如表 test_2 的每个分片都有 3 个副本,那么以第 8 个分片为例,它的所有副本的 zk_path 就都应该配成: ```sql /clickhouse/tables/08/test_2 ``` 然后是 replica_name,这个就比较简单了,因为要区分同一个分区内多个副本,显然它们要有不同的名称。所以上面读起来很拗口的第二个句话就解释完了,对于 replica_name 而言,同一张数据表的同一个分片的不同副本,应该定义不同的名称,这里我直接使用 IP 地址替代了。 ### 三、数据分片 通过引入数据副本,虽然能够有效降低数据的丢失风险(多份存储),并提升查询的性能(分摊查询、读写分离),但是仍然有一个问题没有解决,那就是数据表的容量问题。 到目前为止,每个副本自身,仍然保存了数据表的全量数据。所以在业务量十分庞大的场景中,依靠副本并不能解决单表的性能瓶颈。想要从根本上解决这类问题,需要借助另外一种手段,即进一步**将数据水平切分**,也就是数据分片。 ClickHouse中的每个服务节点都可称为一个shard(分片)。从理论上来讲,假设有N(N>=1)张数据表A,分布在N个ClickHouse服务节点,而这些数据表彼此之间没有重复数据,那么就可以说数据表A拥有N个分片。然而在工程实践中,如果只有这些分片表,那么整个Sharding(分片)方案基本是不可用的。对于一个完整的方案来说,还需要考虑数据在写入时,如何被均匀地写至各个shard,以及数据在查询时,如何路由到每个shard,并组合成结果集。所以,ClickHouse的数据分片需要结合Distributed表引擎一同使用,如图所示。  Distributed表引擎自身不存储任何数据,它能够作为分布式表的一层透明代理,在集群内部自动开展数据的写入、分发、查询、路由等工作。 *附:* *本文摘自《ClickHouse原理解析与应用实践》 — 朱凯*
标签:
ClickHouse
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://www.lilinchao.com/archives/2049.html
上一篇
07.ClickHouse之SQL操作
下一篇
09.ClickHouse查看执行计划
取消回复
评论啦~
提交评论
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
标签云
Quartz
设计模式
Beego
Tomcat
SpringCloud
Spark
nginx
Typora
排序
线程池
Stream流
Ubuntu
随笔
Jenkins
FileBeat
容器深入研究
国产数据库改造
Spark Core
数据结构和算法
Azkaban
Yarn
Sentinel
Spark RDD
SpringBoot
前端
序列化和反序列化
Eclipse
Java工具类
CentOS
GET和POST
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞