李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
什么是OLAP
Leefs
2022-04-26 AM
1892℃
0条
[TOC] ### 一、介绍 OLAP 名为联机分析处理,又可以称之为多维分析处理,是由关系型数据之父于 1993 年提出的概念。顾名思义,它指的是通过多种不同的维度审视数据,进行深层次分析。维度可以看成是观察数据的一种视角,例如人类能看到的世界是三维的,它包含长、宽、高三个维度。直接一点理解,维度就好比是一张数据表的字段,而多维分析则是基于这些字段进行聚合查询。那么多维分析通常都包含哪些基本操作呢?为了更好地理解多维分析的概念,可以通过对一个立方体的图像进行具象化来描述。 #### 示例 **以如下一张销售明细表为例:** 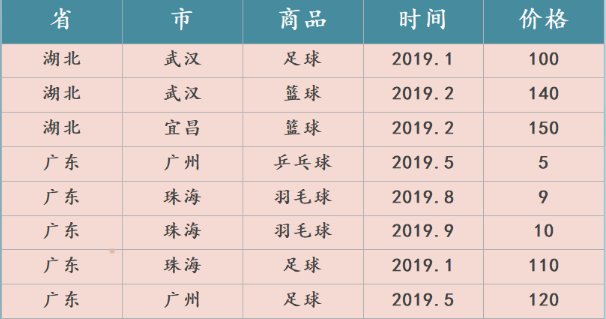 **那么数据立方体可以进行如下操作:** + **下钻:从高层次向低层次明细数据进行穿透。例如从 "省" 下钻到 "市",从 "湖北省" 穿透到 "武汉" 和 "宜昌" 。**  + **上卷:和下钻相反,从低层次向高层次汇聚。例如从 "市" 汇聚到 "省",将 "武汉" 和 "宜昌" 汇聚成 "湖北"。**  + **切片:观察立方体的一层,将一个或多个维度设为单个固定的值,然后观察剩余的维度,例如将商品维度固定为 "足球"。**  + **切块:和切片类似,只是将单个固定值变成多个固定值。例如将商品维度固定为"足球"、"篮球" 和 "乒乓球"。**  + **旋转:旋转立方体的一面,如果要将数据映射到一张二维表,那么就要进行旋转,等同于行列转换。** ### 二、OLAP架构分类 为了实现上述操作,将常见的 OLAP 架构大致分为三类。 **第一类架构称为 ROLAP(Relational OLAP,关系型 OLAP),顾名思义,它直接使用关系模型构建,数据模型常使用星型模型或者雪花模型,这是最先能够想到、也是最为直接的实现方法** > **星型模型:事实表周围的维度表只能有一层;** > > **雪花模型:事实表周围的维度表可以有多层。** 因为 OLAP 概念在最初提出的时候,就是建立在关系型数据库之上的,多维分析的操作可以直接转成 SQL 查询。例如,通过上卷操作查看省份的销售额,就可以转成类似下面的 SQL 语句: ```mysql SELECT SUM(价格) FROM 销售数据表 GROUP BY 省; ``` 但是这种架构对数据的实时处理能力要求很高,试想一下,如果对一张存有上亿条记录的表同时执行数十个字段的GROUP BY查询,将会发生什么事情? **第二类架构称为 MOLAP(Multidimensional OLAP,多维型 OLAP),它的出现就是为了缓解 ROLAP 性能问题。** MOLAP 使用多维数组的形式保存数据,其核心思想是借助预先聚合结果(说白了就是提前先算好,然后将结果保存起来),使用空间换取时间的形式从而提升查询性能。也就是说,用更多的存储空间换得查询时间的减少,其具体的实现方式是依托立方体模型的概念。首先,对需要分析的数据进行建模,框定需要分析的维度字段;然后,通过预处理的形式,对各种维度进行组合并事先聚合;最后,将聚合结果以某种索引或者缓存的形式保存起来(通常只保留聚合后的结果,不存储明细数据),这样一来,在随后的查询过程中,可以直接利用结果返回数据。 **但是这种架构显然并不完美,原因如下**: + 预聚合只能支持固定的分析场景,所以它无法满足自定义分析的需求。 + 维度的预处理会导致数据膨胀,这里可以做一次简单的计算,以上面的销售明细表为例,如果数据立方体包含了 5 个维度(字段),那么维度的组合方式就有 \*[Math Processing Error]25\* 种。维度组合爆炸会导致数据膨胀,这样会造成不必要的计算和存储开销。此外,用户并不一定会用到所有维度的组合,那么没有被用到的组合将会浪费。 + 另外,由于使用了预聚合的方式,数据立方体会有一定的滞后性,不能实时地进行数据分析。所以对于在线实时接收的流量数据,预聚合还需要考虑如何及时更新数据。而且立方体只保留了聚合后的结果数据,因此明细数据是无法查询的。 **第三类架构称为 HOLAP(Hybrid OLAP,混合架构的OLAP),这种思路可以理解成 ROLAP 和 MOLAP 两者的组合,这里不再展开,我们重点关注 ROLAP 和 MOLAP。** ### 三、OLAP 实现技术的演进 在介绍了 OLAP 几种主要的架构之后,再来看看它们背后技术的演进过程,我们把这个演进过程划分为两个阶段。 + 第一个可以称为传统关系型数据库阶段。在这个阶段中,OLAP 主要基于以 Oracle、MySQL 为代表的一种关系型数据库实现。在 ROLAP架构下,直接使用这些数据作为存储与计算的载体;在 MOLAP 架构下,则借助物化视图的方式实现数据立方体。在这个时期,不论是 ROLAP 还是 MOLAP,在数据体量大、维度数目多的情况下都存在严重的性能问题,甚至存在根本查询不出结果的情况。 + 第二个阶段可以称为大数据技术阶段。由于大数据技术的普及,人们开始使用大数据技术重构 ROLAP 和 MOLAP。以 ROLAP 架构为例,传统关系型数据库就被 Hive 和 SparkSQL 这类新兴技术所取代。虽然,以 Spark 为代表的分布式计算系统,相比 Oracle 这类传统数据库而言,在面向海量数据的处理性能方面已经优秀很多,但是直接把它们作为面向终端用户的在线查询系统则还是太慢了。我们的用户普遍缺乏耐心,如果一个查询响应需要几十秒甚至数分钟才能返回,那么这套方案就完全行不通。再看 MOLAP 架构,MOLAP 背后也转为依托 MapReduce 或 Spark 这类新兴技术,将其作为立方体的计算引擎,进行立方体的构建,其预聚合结构的存储载体也转向 HBase 这类高性能分布式数据库。大数据技术阶段,主流 MOLAP 架构已经能够在亿万级数据的体量下,实现毫秒级的查询,但我们说 MOLAP 架构会存在维度爆炸、数据同步实时性不高的问题。 不难发现,虽然 OLAP 在经历了大数据技术的洗礼之后,其各方面性能已经有了脱胎换骨式的改观,但不论是 ROLAP 还是 MOLAP,仍然存在各自的痛点。可如果单纯从模型角度考虑,很明显 ROLAP 要更胜一筹,因为关系型数据库的存在,所以关系模型拥有最好的 "群众基础",也更简单且容易理解。它直接面向明细数据查询,由于不需要预处理,也就自然没有预处理带来的负面影响(维度组合爆炸、数据实时性、更新问题)。 *附参考原文链接地址:* *https://www.cnblogs.com/traditional/p/15218565.html*
标签:
Hadoop
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://www.lilinchao.com/archives/2019.html
上一篇
07.Azkaban条件工作流介绍
下一篇
01.ClickHouse介绍
取消回复
评论啦~
提交评论
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
标签云
SpringCloud
VUE
MyBatisX
Azkaban
递归
Hive
JavaWeb
Flink
SpringBoot
Shiro
Yarn
Python
机器学习
数据结构和算法
Kibana
人工智能
BurpSuite
稀疏数组
Hadoop
MyBatis-Plus
前端
数学
Java阻塞队列
排序
CentOS
哈希表
Elastisearch
Thymeleaf
Docker
队列
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞