李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
03.FastDFS整体架构
Leefs
2022-03-02 AM
865℃
0条
[TOC] ### 一、**FastDFS的存储策略** 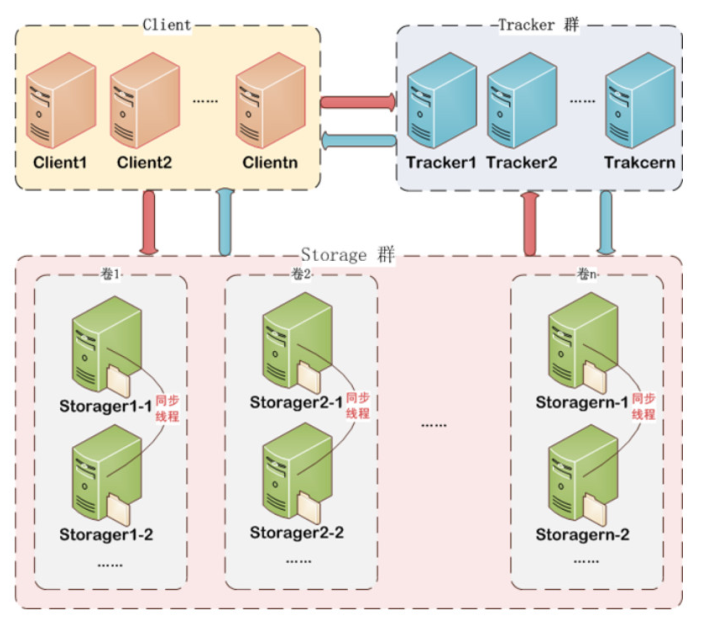 **说明** + 为了支持大容量,存储节点(服务器)采用了分卷(或分组)的组织方式。 + 存储系统由一个或多个卷组成,卷与卷之间的文件是相互独立的,所有卷的文件容量累加就是整个存储系统中的文件容量。 + 一个卷可以由一台或多台存储服务器组成,一个卷下的存储服务器中的文件都是相同的,卷中的多台存储服务器起到了冗余备份和负载均衡的作用。 + 在卷中增加服务器时,同步已有的文件由系统自动完成,同步完成后,系统自动将新增服务器切换到线上提供服务。 + 当存储空间不足或即将耗尽时,可以动态添加卷。只需要增加一台或多台服务器,并将它们配置为一个新的卷,这样就扩大了存储系统的容量。 ### 二、文件上传过程 FastDFS向使用者提供基本文件访问接口,比如upload、download、append、delete等,以客户端库的方式提供给用户使用。 Storage Server会定期的向Tracker Server发送自己的存储信息。当Tracker Server Cluster中的Tracker Server不止一个时,各个Tracker之间的关系是对等的,所以客户端上传时可以选择任意一个Tracker。 当Tracker收到客户端上传文件的请求时,会为该文件分配一个可以存储文件的group,当选定了group后就要决定给客户端分配group中的哪一个storage server。当分配好storage server后,客户端向storage发送写文件请求,storage将会为文件分配一个数据存储目录。然后为文件分配一个fileid,最后根据以上的信息生成文件名存储文件。  **说明** 1、Storage Server 定时向 Tracker Server 发送自己的存储信息; 2、Client 调用 FastDFS API 发送上传连接请求给 Tracker Server; 3、Tracker Server 查询可用的 Storage Server 信息; 4、Tracker Server 将该信息( Storage 的 ip 和端口号 )返回给 Client; 5、Client 调用 FastDFS API 上传文件给 Storage Server; 6、Storage Server 生成文件 id ( file_id ); 7、Storage Server 将上传内容写入磁盘; 8、Storage Server 返回 file_id 给 Client ; 9、Client 层将存储文件信息写入数据库。 ### 三、**文件存储目录信息** 客户端上传文件后存储服务器将文件ID返回给客户端,此文件ID用于以后访问该文件的索引信息。 **文件索引信息包括**:组名,虚拟磁盘路径,数据两级目录,文件名。  + **组名(group1)**:文件上传后所在的storage组名称,在文件上传成功后有storage服务器返回,需要客户端自行保存。 + **虚拟磁盘路径(M00)**:storage配置的虚拟路径,与磁盘选项`store_path*`对应。如果配置了`store_path0`则是M00,如果配置了`store_path1`则是M01,以此类推。 + **数据两级目录(/02/44)**:storage服务器在每个虚拟磁盘路径下创建的两级目录,用于存储数据文件。( 因为文件太多放在一个目录下的话容易卡死 )。 + **文件名**:与文件上传时不同。是由存储服务器根据特定信息生成,文件名包含:源存储服务器IP地址、文件创建时间戳、文件大小、随机数和文件拓展名等信息。 ### 四、**文件同步** + 写文件时,客户端将文件写至group内一个storage server即认为写文件成功,storage server写完文件后,会由后台线程将文件同步至同group内其他的storage server。 + 每个storage写文件后,同时会写一份binlog,binlog里不包含文件数据,只包含文件名等元信息,这份binlog用于后台同步,storage会记录向group内其他storage同步的进度,以便重启后能接上次的进度继续同步;进度以时间戳的方式进行记录,所以最好能保证集群内所有server的时钟保持同步。 + storage的同步进度会作为元数据的一部分汇报到tracker上,tracke在选择读storage的时候会以同步进度作为参考。 ### 五、文件下载  客户端uploadfile成功后,会拿到一个storage生成的文件名,接下来客户端根据这个文件名即可访问到该文件。 跟upload file一样,在downloadfile时客户端可以选择任意tracker server。tracker发送download请求给某个tracker,必须带上文件名信息,tracke从文件名中解析出文件的group、大小、创建时间等信息,然后为该请求选择一个storage用来服务读请求。 *附参考文章链接:* *https://www.cnblogs.com/fangwu/p/8178781.html* *https://www.cnblogs.com/dalianpai/p/11827311.html*
标签:
FastDFS
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://www.lilinchao.com/archives/1930.html
上一篇
02.FastDFS操作命令
下一篇
10.Table API和Flink SQL之窗口操作
取消回复
评论啦~
提交评论
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
标签云
Map
Hive
BurpSuite
数据结构和算法
Flume
稀疏数组
Tomcat
Java
微服务
Eclipse
SpringBoot
持有对象
Spark RDD
Spark Core
Shiro
ClickHouse
JavaWeb
SQL练习题
排序
Golang
正则表达式
Elastisearch
Kibana
DataX
Flink
高并发
MySQL
Scala
Spark SQL
Docker
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞