李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
Java
正文
MySQL高级应用窗口函数(一)
Leefs
2021-11-17 PM
1213℃
0条
[TOC] ### 前言 一般我们经常使用的函数分为两类:普通函数和聚合函数。但是这两类函数对于一些相对复杂的报表统计分析场景实现起来相对麻烦。 本篇将讲述第三种函数:窗口函数。 MYSQL 从 8.0.2 版本起开始支持窗口函数,这个功能在大多商业数据库和部分开源数据库中早已支持。 我们平常使用SQL语句中Hive、SparkSQL、Oracle、SQL Server都很早就开始支持窗口函数。 本来本篇内容想通过SparkSQL来进行叙述,但是考虑到MySQL对大家来说相对较熟悉,所以窗口函数系列文章将围绕MySQL 8.0版本进行叙述。 + 安装MySQL 8.0数据库可以看本篇教程:[CentOS7.X安装MySQL8.0教程](https://lilinchao.com/archives/1632.html) + 注意:MySQL 8.0.2之前的版本运行窗口函数将会报错。 ### 一、业务场景 我们先从一个业务场景入手,来对窗口函数做一个简单的认识 #### 1.1 需求 > 对下图表1中的2020-09月份到2021-03月份数据,根据销售额按照月份进行累加得到全年累计销售额,如下图表2 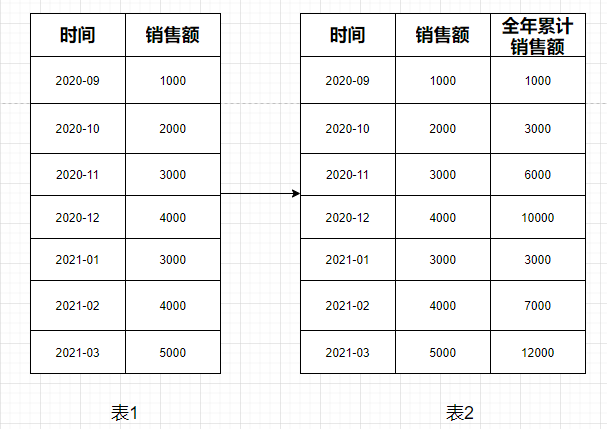 **全年累计销售额计算过程** + 2020-09月到2020-12月根据月份进行按顺序逐月进行累加 ``` 2020-09:1000 2020-10:1000 + 2000 = 3000 2020-11:3000 + 3000 = 6000 2020-12:6000 + 4000 = 10000 ``` + 2021-01月到2021-03月根据月份进行按顺序逐月进行累加 ``` 2021-01:3000 2021-02:3000 + 4000 = 7000 2021-03:7000 + 5000 = 12000 ``` **上方总结起来就一句话:按照年份分组,按照月份累加** (我想这样该讲的很明白了,继续往下) #### 1.2 通过普通聚合函数进行实现 ```mysql SELECT time, sales,( SELECT SUM( sales ) FROM cum_sales WHERE LEFT ( time, 4 )= LEFT ( c.time, 4 ) AND time <= c.time ) totalcount FROM cum_sales c ``` 上方代码是通过普通聚合函数进行实现,逻辑也稍微复杂一下,因为不是重点也不在此过多介绍。 #### 1.3 窗口函数进行实现 ```mysql SELECT time, sales, sum( sales ) over ( PARTITION BY LEFT ( time, 4 ) ORDER BY time ASC ) AS totalcount FROM ``` 通过窗口函数`sum()over()`进行实现,和普通聚合函数相比实现逻辑更加清晰 通过上方普通函数和窗口函数进行比较,不难发现窗口函数可以**处理相对复杂的报表统计分析场景**,简化代码逻辑。 ### 二、概述 #### 2.1 简介 窗口函数叫法有很多,包括分析函数、开窗函数、分析窗口函数等。 窗口函数用于为行定义一个窗口(这里的窗口是指运算将要操作的行的集合),它对一组值进行操作,不需要使用GROUP BY子句对数据进行分组,能够在同一行中同时返回基础行的列和聚合列。 **普通的聚合函数只能用来计算一行内的结果或把所有行聚合成一行结果,而窗口函数支持为每一行生成一个结果。** #### 2.2 语法 窗口函数基本语法结构: ```mysql 函数名([expr]) over(partition by <要分列的组> order by <要排序的列> rows between <数据范围>) ``` + 也可以理解为 ``` 分析函数 over(partition by 列名 order by 列名 rows between 开始位置 and 结束位置) ``` **说明** 窗口函数都是和分析函数一起使用:`分析函数 + over()` 分析函数包括: + 普通聚合函数:sum()、avg()、max()等 + 排名函数:rank()、dense_rank()、row_number()等 + 偏移函数:lag()、lead()等 over关键字,用来指定函数执行的窗口范围,其中包含三个分析子句: + **分区(partition by)子句:**用于划分窗口分区,如果没有指定partition by子句,则整个查询与分析结果集作为一个窗口分区。 + **排序(order by)子句:**用于对窗口分区内的行进行排序,可以和partition子句配合使用,也可以单独使用。如果没有partition子句,数据范围则是整个表的数据行。 注意:使用order by子句对重复的数值进行排序时,排序结果不稳定。如果您希望每次排序结果相同,可指定多个列进行排序。例如`order by request_time, request_method`。 + **窗口(rows)子句:**就是进行函数分析时要处理的数据范围,属于当前分区的一个子集,通常用来作为滑动窗口使用。rows元素在窗口分区内对行进一步限制。rows元素不适用于排名函数。 over()可以为空,如果为空,则意味着包含满足where条件的所有行,窗口函数基于所有行进行计算 #### 2.3 窗口范围 + 取当前行和前面两行 ```mysql rows between 2 preceding and current row ``` + 包括本行和之前所有行 ```mysql rows between unbounded preceding and current row ``` + 包括本行和之后所有行 ```mysql rows between current row and unbounded following ``` + 包括本行和前面三行 ```mysql rows between 3 preceding and current row ``` + 从前面三行和下面一行,总共五行 ```mysql rows between 3 preceding and 1 following ``` + 当order by后面缺少窗口从句条件,窗口规范默认是 ```mysql rows between unbounded preceding and current row ``` + 当order by和窗口从句都缺失,窗口规范默认是 ```mysql rows between unbounded preceding and unbounded following ``` **说明** | 名词 | 含义 | | ------------------- | ---------------------------------------- | | preceding | 往前 | | following | 往后 | | current row | 当前行 | | unbounded | 起点(一般结合preceding,following使用) | | unbounded preceding | 表示该窗口最前面的行(起点) | | unbounded following | 表示该窗口最后面的行(终点) | ### 三、函数列表  ### 结尾 如果需要本篇开头示例的表和数据,可以在微信公众号:【Java和大数据进阶】回复【sql】即可获取。 *附参考文章链接:* *https://www.jianshu.com/p/3f3cf58472ca* *https://help.aliyun.com/document_detail/63972.html#section-42t-cj8-nio*
标签:
MySQL
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://www.lilinchao.com/archives/1635.html
上一篇
CentOS7.X安装MySQL8.0教程
下一篇
MySQL高级应用窗口函数(二)
取消回复
评论啦~
提交评论
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
标签云
Elastisearch
查找
Tomcat
Scala
HDFS
正则表达式
Java编程思想
FastDFS
DataWarehouse
Beego
Http
前端
Jquery
Spark Core
Livy
国产数据库改造
Java
微服务
Flume
设计模式
JVM
Azkaban
Spark RDD
Nacos
Zookeeper
Sentinel
Stream流
DataX
Ubuntu
机器学习
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞