李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
02.SparkSQL数据模型DataFrame和DataSet介绍
Leefs
2021-07-16 PM
1201℃
0条
# 02.SparkSQL数据模型DataFrame和DataSet介绍 ### 前言 本篇在上篇介绍SparkSQL概念的基础上对DataFrame和DataSet概念进行扩展 ### 一、DataFrame介绍 #### 1.1 DataFrame概念 DataFrame的前身是SchemaRDD,从Spark 1.3.0开始SchemaRDD更名为DataFrame。 与SchemaRDD的主要区别是:**DataFrame不再直接继承自RDD,而是自己实现了RDD的绝大多数功能。**你仍旧可以在DataFrame上调用rdd方法将其转换为一个RDD。 在Spark中,DataFrame是一种以RDD为基础的**分布式数据集**,类似于传统数据库的二维表格,DataFrame带有Schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型,但底层做了更多的优化。DataFrame可以从很多数据源构建,比如:已经存在的RDD、结构化文件、外部数据库、Hive表。 由于 Spark SQL 支持多种语言的开发,所以每种语言都定义了 `DataFrame` 的抽象,主要如下: | 语言 | 主要抽象 | | ------ | -------------------------------------------- | | Scala | Dataset[T] & DataFrame (Dataset[Row] 的别名) | | Java | Dataset[T] | | Python | DataFrame | | R | DataFrame | #### 1.2 DataFrame和RDD的区别 DataFrame 和 RDDs 最主要的区别在于一个面向的是结构化数据,一个面向的是非结构化数据。 **以Person实体为例探究** 当我们以两种不同的方式读取到Person数据,Person会作为RDD的类型参数,但是Spark无法知晓内部结构,而dataFrame可以清楚加载到Person实体的内部结果和具体的数据: 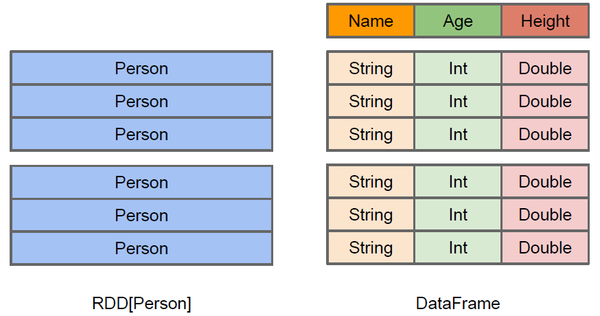 **解析:** + 左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解 Person类的内部结构。 + 右侧的DataFrame却提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么,DataFrame多了数据的结构信息,即schema。这样看起来就像一张表了,DataFrame还配套了新的操作数据的方法,`DataFrame API` + DataFrame还引入了`off-heap`,意味着JVM堆以外的内存, 这些内存直接受操作系统管理(而不是JVM)。Spark能够以二进制的形式序列化数据(不包括结构)到off-heap中, 当要操作数据时, 就直接操作off-heap内存. 由于Spark理解schema, 所以知道该如何操作。  RDD是分布式的Java对象的集合。DataFrame是分布式的Row对象的集合。DataFrame除了提供了比RDD更丰富的算子以外,更重要的特点是提升执行效率、减少数据读取以及执行计划的优化。 有了DataFrame这个高一层的抽象后,我们处理数据更加简单了,甚至可以用SQL来处理数据了,对开发者来说,易用性有了很大的提升。 不仅如此,通过DataFrame API或SQL处理数据,会自动经过Spark 优化器(Catalyst)的优化,即使你写的程序或SQL不高效,也可以运行的很快。 #### 1.3 DataFrame和RDD的优缺点 > **RDD** **优点** 1. 编译时类型安全 编译时就能检查出类型错误 2. 面向对象的编程风格 直接通过对象调用方法的形式来操作数据 **缺点** 1. 数据序列化和反序列化的性能开销 无论是集群间的通信, 还是IO操作都需要对对象的结构和数据进行序列化和反序列化。 2. GC的性能开销 频繁的创建和销毁对象会带来GC(jvm内存回收机制:垃圾回收),GC处理的时候,其他进程都会暂停。 > DataFrame **优点** DataFrame引入了schema和off-heap 1. chema就是对于DataFrame数据的结构信息进行描述 在进行数据序列化的时候,就不需要针对于数据的结构进行序列化了,直接把数据本身进行序列化就可以了,减少数据的网络传输。 解决了RDD在数据进行序列化和反序列化性能开销很大这个缺点。 2. off-heap不在使用jvm堆中的内存来构建大量的对象,而是直接使用操作系统层面上的内存 解决了RDD在堆中频繁创建大量的对象造成GC这个缺点。 **缺点** DataFrame引入了schema和off-heap解决了RDD的缺点,同时也丢失了RDD的优点 1. 编译时不在是类型安全 2. 也不具备面向对象编程这种风格 #### 1.4 DataFrame 和 RDDs 应该如何选择 - 如果你想使用函数式编程而不是 DataFrame API,则使用 RDDs; - 如果你的数据是非结构化的 (比如流媒体或者字符流),则使用 RDDs, - 如果你的数据是结构化的 (如 RDBMS 中的数据) 或者半结构化的 (如日志),出于性能上的考虑,应优先使用 DataFrame。 ### 二、DataSet介绍 #### 2.1 DataSet概念 Dataset 也是分布式的数据集合,在 Spark 1.6 版本被引入,它集成了 RDD 和 DataFrame 的优点,具备强类型的特点,同时支持 Lambda 函数,但只能在 Scala 和 Java 语言中使用。 在 Spark 2.0 后,为了方便开发者,Spark 将 DataFrame 和 Dataset 的 API 融合到一起,提供了结构化的 API(Structured API),即用户可以通过一套标准的 API 就能完成对两者的操作。  注意:DataFrame 被标记为 `Untyped API`,而 DataSet 被标记为 `Typed API`。 **Untyped和Typed** + DataFrame 的`Untyped` 是相对于语言或 API 层面而言,它确实有明确的 Scheme 结构,即列名,列类型都是确定的,但这些信息完全由 Spark 来维护,Spark 只会在运行时检查这些类型和指定类型是否一致。这也就是为什么在 Spark 2.0 之后,官方推荐把 DataFrame 看做是 `DatSet[Row]`,Row 是 Spark 中定义的一个 `trait`,其子类中封装了列字段的信息。 + DataSet 是 `Typed` 的,即强类型。如下面代码,DataSet 的类型由 Case Class(Scala) 或者 Java Bean(Java) 来明确指定的,在这里即每一行数据代表一个 `Person`,这些信息由 JVM 来保证正确性,所以字段名错误和类型错误在编译的时候就会被 IDE 所发现。 #### 2.2 静态类型与运行时类型安全 静态类型 (Static-typing) 与运行时类型安全 (runtime type-safety) 主要表现如下: 在实际使用中,如果你用的是 Spark SQL 的查询语句,则直到运行时你才会发现有语法错误,而如果你用的是 DataFrame 和 Dataset,则在编译时就可以发现错误 (这节省了开发时间和整体代价)。 **DataFrame 和 Dataset 主要区别在于:** 在 DataFrame 中,当你调用了 API 之外的函数,编译器就会报错,但如果你使用了一个不存在的字段名字,编译器依然无法发现。 Dataset 的 API 都是用 Lambda 函数和 JVM 类型对象表示的,所有不匹配的类型参数在编译时就会被发现。 以上这些最终都被解释成关于类型安全图谱,对应开发中的语法和分析错误。在图谱中,Dataset 最严格,但对于开发者来说效率最高。  #### 2.3 DataSet和DataFrame的对比 + DataFrame也可以叫做DataSet[Row],每一行的类型都是Row,不解析我们就无法知晓其中有哪些字段,每个字段又是什么类型。我们只能通过getAs[类型]或者row(i)的方式来获取特定的字段内容 + 而在Dataset中,每一行的类型是不一定的,在自定义了case class之后就可以很自由的获取每一行的信息。 + DataSet可以理解成DataFrame的一种特例,DataFrame = DataSet[Row],主要区别是DataSet每一个record存储的是一个强类型值而不是一个Row。 + 可以通过 as 方法将 DataFrame 转换为 DataSet。Row 是一个类型,跟 Car、Person 这些类型一样, 所有的表结构信息都用 Row 来表示。 DataFrame只是知道字段,但是不知道字段的类型,所以在执行这些操作的时候是没办法在编译的时候检查是否类型失败的,比如你可以对一个String进行减法操作,在执行的时候才报错,而DataSet不仅仅知道字段,而且知道字段类型,所以有更严格的错误检查。 附参考文章链接: https://www.cnblogs.com/shun7man/p/13194082.html
标签:
Spark
,
Spark SQL
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://www.lilinchao.com/archives/1328.html
上一篇
01.SparkSQL概述
下一篇
03.IDEA创建SparkSQL环境对象
取消回复
评论啦~
提交评论
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
标签云
Shiro
持有对象
数据结构
FileBeat
查找
Spark
Filter
JavaWeb
工具
Spring
国产数据库改造
Tomcat
散列
BurpSuite
Spark RDD
排序
正则表达式
Python
线程池
Spark Streaming
Typora
Kibana
Java编程思想
随笔
JavaWEB项目搭建
Http
SpringBoot
数据结构和算法
Elasticsearch
Hive
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞