李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
06.【转载】Spark RDD行动算子
Leefs
2021-06-29 AM
1166℃
0条
[TOC] ## 行动算子 如何理解行动算子? ```scala val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4)) // 转换算子:将旧的RDD封装为新的RDD,形成transform chain,不会执行任何Job val mapRdd: RDD[Int] = rdd.map(_ * 2) // 行动算子:其实就是触发作业(Job)执行的方法,返回值不再是RDD mapRdd.collect() ``` > `collect()`等行动算子在底层调用环境对象的`runJob`方法,会创建ActiveJob,并提交执行。 如果只有转换算子,而没有行动算子,那么Job不会执行,只是功能上的封装拓展。 转换算子将功能不断封装,最终由行动算子执行Job,这比封装一次执行一次,更加高效。 还有一个重要特点,转换算子的返回值是`RDD`,行动算子的返回值是scala集合或标量。 #### collect ```scala def collect(): Array[T] ``` 说明:会将不同分区的数据**按照分区顺序**采集到**Driver端内存**中,形成数组 ```scala val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4)) val arr: Array[Int] = rdd.collect() println(arr.mkString(",")) //1,2,3,4 ==> 保持顺序 ``` - 其他: ```scala val rdd = sc.makeRDD(List(4,2,3,1)) // count : 数据源中数据的个数 val cnt: Long = rdd.count() // first : 获取数据源中数据的第一个元素 val first: Int = rdd.first() // take : 返回一个由 RDD 的前 n 个元素组成的数组 Array(4, 2, 3) val ints: Array[Int] = rdd.take(3) // takeOrdered : 返回该 RDD 排序后的前 n 个元素组成的数组 Array(1, 2, 3) val ints1: Array[Int] = rdd.takeOrdered(3) // top: 与takeOrdered正好反序 val ints2: Array[Int] = rdd.top(3) // Array(4, 3, 2) ``` 以count为例,说明action算子执行的流程: - 每个 task 统计每个 partition 里 records 的个数,比如 partition 0 里含有 5 个 records,partition 1 里含有 10 个 records 等 。 - task 执行完后,driver 收集每个 task 的执行结果,然后进行 sum()。 总结:分区内计算(并行),分区间汇总(Driver) #### reduce ```scala def reduce(f: (T, T) => T): T ``` 说明:对 RDD 中的元素进行**二元计算**,分区内与分区间计算规则相同。 ```scala // 单值类型 f:(Int, Int) => Int val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4)) val reduceRDD: Int = rdd.reduce((x, y) => x + y) // 10 // KV类型: f:((string,Int), (string,Int)) => (string,Int) val rdd1: RDD[(String, Int)] = sc.makeRDD(List(("hello", 2), ("hello", 3))) val reduceRDD1: (String, Int) = rdd1.reduce( (t1, t2) => { (t1._1, t1._2 + t2._2) } ) // ("hello", 5) ``` #### aggregate ```scala def aggregate(zeroValue: U) (seqOp: (U, T) => U, combOp: (U, U) => U): U ``` 说明:分区的数据通过**初始值**先和**分区内**的数据进行聚合,然后再和**初始值**进行**分区间**的数据聚合 ```scala val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2) val res: Int = rdd.aggregate(0)(_ + _, _ + _) //res = 10 val res1: Int = rdd.aggregate(10)(_ + _, _ + _) //分区内:13 和 17;分区间 13 + 17 + 10 = 40,故 res = 40 ``` - 区别: > aggregateByKey : 初始值只会参与分区内计算;仅适用于 KV 类型 > > aggregate : 初始值会参与分区内计算,并且和参与分区间计算;可使用任意类型 #### fold ```scala def fold(zeroValue: T)(op: (T, T) => T): T ``` 说明:当分区内与分区间的计算规则相同时,它是aggregate 的简化版操作 ```scala val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2) val result = rdd.aggregate(0)(_+_, _+_) val result1 = rdd.fold(0)(_+_) //res=10 ``` #### countByKey ```scala def countByKey(): Map[K, Long] ``` 说明:统计每种 key 的个数 ```scala // 针对KV类型,计算每个Key出现的个数(并不是聚合!) val rdd = sc.makeRDD(List( ("a", 1),("a", 2),("a", 3),("b",2) )) val countKeyRdd: collection.Map[String, Long] = rdd.countByKey() println(countKeyRdd) // Map(a -> 3, b -> 1) ``` - 补充:countByValue ```scala // 任意类型的集合 val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2) val countValRdd: collection.Map[Int, Long] = rdd.countByValue() println(countValRdd) // Map(4 -> 1, 2 -> 1, 1 -> 1, 3 -> 1) ``` #### foreach ```scala def foreach(f: T => Unit): Unit ``` 说明:**分布式遍历** RDD 中的每一个元素,调用指定函数 ```scala val rdd = sc.makeRDD(List(1,2,3,4), 2) // 先collect(),在Driver端内存 循环遍历 rdd.collect().foreach(println) 1 2 3 4 ``` ```scala val rdd = sc.makeRDD(List(1,2,3,4), 2) // rdd.foreach 其实是Executor端内存数据打印(分布式打印) rdd.foreach(println) 3 1 4 2 ``` 图解: 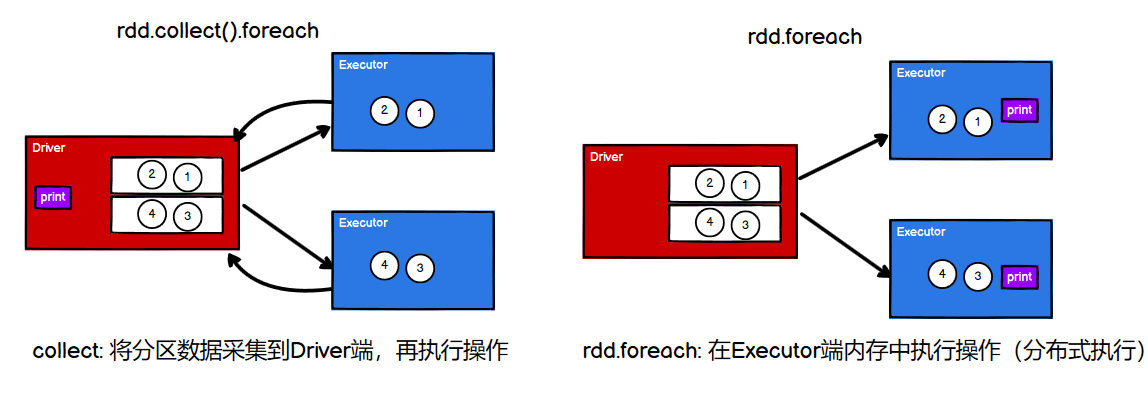 类似的,行动算子 `foreachPartition(f: Iterator[T] => Unit)` 针对RDD的每个分区执行一次。 #### save 将数据保存到不同格式的文件中 ```scala val rdd = sc.makeRDD(List(("a", 1),("a", 2),("a", 3))) // 保存成 Text 文件(最常用) rdd.saveAsTextFile("output") // 序列化成对象保存到文件 rdd.saveAsObjectFile("output1") //保存成 Sequencefile 文件,该方法要求数据的格式必须为K-V类型 rdd.saveAsSequenceFile("output2") ``` 该方法可以用来查看分区结果: ```scala val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2) rdd.saveAsTextFile("output") ```  *附:* 原文链接地址:https://juejin.cn/post/6957937654360965157#heading-35
标签:
Spark
,
Spark Core
,
Spark RDD
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://www.lilinchao.com/archives/1303.html
上一篇
05.【转载】Spark RDD转换算子
下一篇
07.Spark RDD序列化
取消回复
评论啦~
提交评论
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
标签云
Docker
Hadoop
Beego
Spark RDD
MyBatis
SpringCloudAlibaba
Stream流
MyBatisX
容器深入研究
MyBatis-Plus
Nacos
算法
Sentinel
Hive
数据结构和算法
Hbase
持有对象
Spring
二叉树
Shiro
Git
Eclipse
ajax
HDFS
nginx
Kibana
序列化和反序列化
工具
gorm
并发编程
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞