李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
CentOS7 Spark Local模式搭建
Leefs
2021-02-21 PM
1208℃
0条
# 07.CentOS7 Spark Local模式搭建 ### 前言 需要提前准备的环境 1. JDK1.8 2. Hadoop 2.8.5(小编安装的Hadoop环境) 3. 系统版本Centos7 本次搭建的Spark版本为3.0.1。 ### 一、Spark Local环境搭建 1. 下载 访问官网:http://spark.apache.org/ 点击Download下载最新版本。 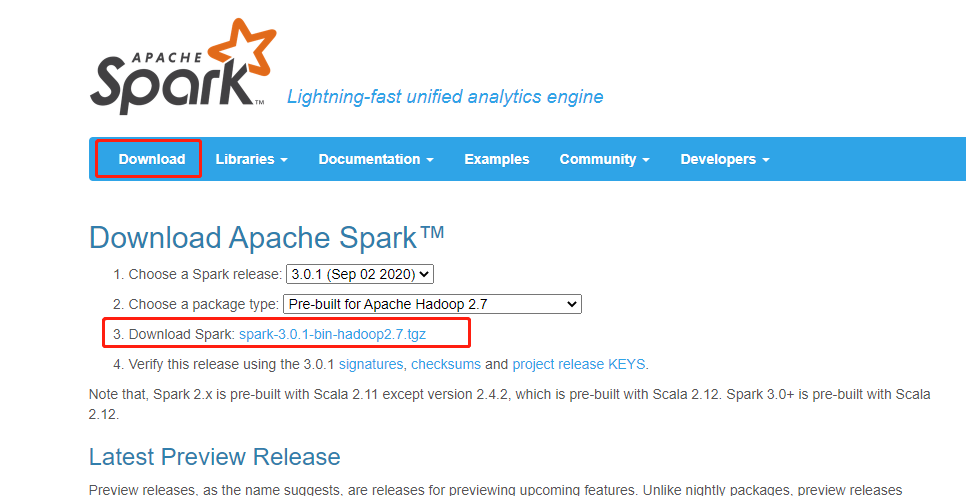 下载spark其实是跟hadoop包对应的,但是我看官网上的都是hadoop2.7 ,而我的hadoop安装的版本是2.8.5应该也不影响。 2. 将下载好的文件上传到服务器上并解压 ``` [root@localhost local]# tar -zxvf /home/sources/spark-3.0.1-bin-hadoop2.7.tgz ``` 3. 添加环境变量 ``` [root@localhost local]# su root [root@localhost local]# vim /etc/profile ``` 内容如下 ``` export JAVA_HOME=/usr/local/jdk1.8.0_241 export SPARK_HOME="/usr/local/spark-3.0.1-bin-hadoop2.7" export PATH=$JAVA_HOME/bin:$SPARK_HOME/bin:$PATH ``` 4. 重新加载资源文件 ``` [root@localhost local]# source /etc/profile ``` 5. 测试 ``` [root@localhost spark-3.0.1-bin-hadoop2.7]$ run-example SparkPi 10 ``` 可以看到正常计算成功。 测试shell ``` [root@localhost local]$ spark-shell ```  ### 二、概念 **1. 基础概念** Local模式就是Spark运行在单节点的模式,通常用于在本机上练手和测试,分为以下三种情况: (1)local:所有计算都运行在一个线程中; (2)local[K]:指定K个线程来运行计算,通常CPU有几个Core(线程数),就指定K为几,最大化利用CPU并行计算能力; (3)local[*]:自动设定CPU的最大Core数; 在API操作中体现在SparkConf的环节(配置信息),将Master(资源管理器)设定为哪种模式,对应几个线程: ```scala val conf = new SparkConf().setMaster("local[*]").setAppName("Application") ``` **2. 官方求PI案例** 直接运行已打成依赖jar包中的指定class ``` [hadoop@localhost spark-3.0.1-bin-hadoop2.7]$ bin/spark-submit \ > --class org.apache.spark.examples.SparkPi \ > --executor-memory 1G \ > --total-executor-cores 2 \ > ./examples/jars/spark-examples_2.12-3.0.1.jar \ > 100 ``` **参数说明** + bin/spark-submit:Spark的bin目录下一个提交任务脚本 + executor-memory:给executor(具体计算功能的承担者)分配1G的内存 + total-executor-cores:指定每个executor使用的cup核数为2个 最后的jar包是已经打成依赖的jar包;这个jar包可以是本地、也可以是HDFS中hdfs://、也可以是来自文件系统file:// path **运行结果** 运行结果如下,该算法是利用蒙特·卡罗算法求PI ``` Pi is roughly 3.1418651141865115 ``` ### 三、通过scala语言测试 **任务**:写一个WordCount的测试Demo程序 (1)在spark-3.0.1-bin-hadoop2.7/input目录下,创建1.txt和2.txt文件 ``` [hadoop@localhost input]$ pwd /usr/local/spark-3.0.1-bin-hadoop2.7/input [hadoop@localhost input]$ cat 1.txt hello spark hello world [hadoop@localhost input]$ cat 2.txt hello spark hello world ``` (2)启动spark-shell ``` [hadoop@localhost spark-3.0.1-bin-hadoop2.7]$ bin/spark-shell ``` (3)运行WordCount的scala程序 ``` scala> sc.textFile("file:///usr/local/spark-3.0.1-bin-hadoop2.7/input").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect res3: Array[(String, Int)] = Array((hello,4), (world,2), (spark,2)) ``` 参数说明 + **textFile("input"):**读取本地文件,/usr/local/spark-3.0.1-bin-hadoop2.7/input文件夹数据; + **flatMap(_.split(" ")):**压平操作,按照空格分割符,将文件每一行数据映射(Map)成一个个单词; + **map((_,1)):**对每一个单词操作,将单词映射为元组(单词,1); + **reduceByKey(_+_):**形同key的value值进行聚合,相加; + **collect:**将数据收集到Driver端展示。
标签:
Spark
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://www.lilinchao.com/archives/1199.html
上一篇
【转载】Spark部署模式介绍
下一篇
CentOS7安装Hadoop3.2集群
取消回复
评论啦~
提交评论
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
标签云
二叉树
Spark
微服务
工具
线程池
正则表达式
前端
Spring
设计模式
Tomcat
JavaSE
Stream流
散列
ajax
FastDFS
HDFS
Git
SQL练习题
Flume
DataWarehouse
排序
Docker
Java
Golang
Scala
Netty
查找
人工智能
RSA加解密
Spark RDD
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞