李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
Spark入门程序WordCount
Leefs
2021-02-21 PM
1553℃
0条
# 05.Spark入门程序WordCount ### 一、问题描述 描述:编写一个Spark应用程序,对1.txt和2.txt文件中的单词进行词频统计 通过Spark core进行实现 ### 二、方法一 **1. 思路** 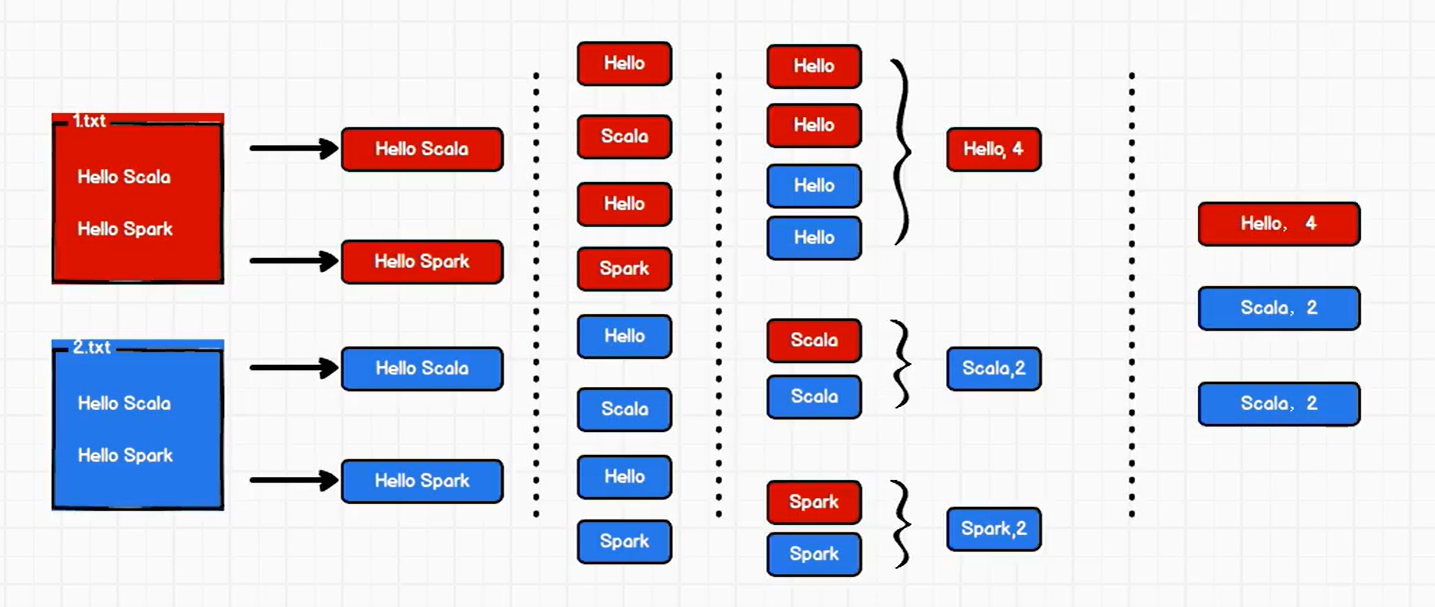 1. 整行读取1.txt和2.txt文件中所有内容 2. 将整行数据拆分,形成一个个单词 3. 根据单词进行分组,将相同的单词放在一组当中,方便统计 4. 对分组后的数据进行转换 5. 将转换结果输出 **2. 代码实现流程** + 建立和Spark框架的连接 + 执行业务操作 + 关闭连接 **3. 代码实现** ```scala package com.llc.spark.code.wc import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object WordCountDemo01 { def main(args: Array[String]): Unit = { // TODO 建立和Spark框架的连接 // JDBC : Connection val sparConf = new SparkConf().setMaster("local").setAppName("WordCount") val sc = new SparkContext(sparConf) // TODO 执行业务操作 // 1. 读取文件,获取一行一行的数据 // hello world val lines: RDD[String] = sc.textFile("datas/*.txt") // 2. 将一行数据进行拆分,形成一个一个的单词(分词) // 扁平化:将整体拆分成个体的操作 // "hello world" => hello, world, hello, world val words: RDD[String] = lines.flatMap(_.split(" ")) // 3. 将数据根据单词进行分组,便于统计 // (hello, hello, hello), (world, world) val wordGroup: RDD[(String, Iterable[String])] = words.groupBy(word=>word) // 4. 对分组后的数据进行转换 // (hello, hello, hello), (world, world) // (hello, 3), (world, 2) val wordToCount = wordGroup.map { case ( word, list ) => { (word, list.size) } } // 5. 将转换结果采集到控制台打印出来 val array: Array[(String, Int)] = wordToCount.collect() array.foreach(println) // TODO 关闭连接 sc.stop() } } ``` **输出结果** ``` (Hello,4) (World,2) (Spark,2) ``` *注意* 如果指定相对路径sc.textFile("datas"),则会报如下错误 ```xml Exception in thread "main" java.lang.RuntimeException: Error while running command to get file permissions : java.io.IOException: (null) entry in command string: null ls -F D:\Codes\llc-blog\demo\datas\1.txt at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:773) at org.apache.hadoop.util.Shell.execCommand(Shell.java:869) at org.apache.hadoop.util.Shell.execCommand(Shell.java:852) at org.apache.hadoop.fs.FileUtil.execCommand(FileUtil.java:1097) ``` ### 三、方法二 **1. 思路**  1. 整行读取1.txt和2.txt文件中所有内容 2. 将整行数据拆分,形成一个个单词 3. 将单词进行结构的转换,方便统计 4. 将转换后的数据进行分组聚合 5. 将转换结果输出 **2. 代码实现** ```scala package com.llc.spark.code.wc import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object WordCountDemo02 { def main(args: Array[String]): Unit = { // TODO 建立和Spark框架的连接 // JDBC : Connection val sparConf = new SparkConf().setMaster("local").setAppName("WordCount") val sc = new SparkContext(sparConf) // TODO 执行业务操作 // 1. 读取文件,获取一行一行的数据 // hello world val lines: RDD[String] = sc.textFile("datas/*.txt") // 2. 将一行数据进行拆分,形成一个一个的单词(分词) // 扁平化:将整体拆分成个体的操作 // "hello world" => hello, world, hello, world val words: RDD[String] = lines.flatMap(_.split(" ")) // 3. 将单词进行结构的转换,方便统计 // word => (word, 1) val wordToOne = words.map(word=>(word,1)) // 4. 将转换后的数据进行分组聚合 // 相同key的value进行聚合操作 // (word, 1) => (word, sum) val wordToSum: RDD[(String, Int)] = wordToOne.reduceByKey(_+_) // 5. 将转换结果采集到控制台打印出来 val array: Array[(String, Int)] = wordToSum.collect() array.foreach(println) // TODO 关闭连接 sc.stop() } } ``` 输出结果 ``` (Hello,4) (World,2) (Spark,2) ```
标签:
Spark
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://www.lilinchao.com/archives/1195.html
上一篇
基于IDEA构建spark开发环境
下一篇
【转载】Spark部署模式介绍
取消回复
评论啦~
提交评论
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
标签云
Sentinel
并发线程
Ubuntu
Filter
数学
排序
HDFS
Spring
数据结构
Elastisearch
Redis
链表
Http
二叉树
Spark RDD
并发编程
前端
Java编程思想
FastDFS
DataWarehouse
持有对象
Kibana
散列
Spark Streaming
JavaWEB项目搭建
JVM
Livy
Tomcat
Java工具类
Typora
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞