03.Spark RDD简介
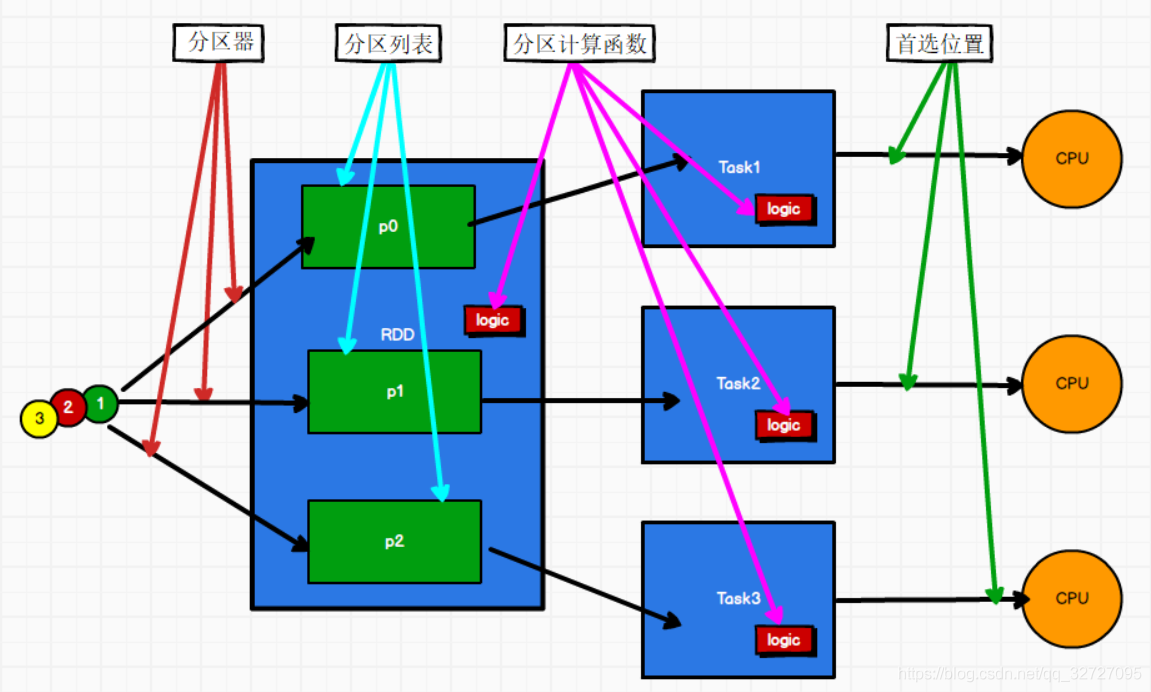
03.Spark RDD简介一、RDD定义RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。弹性存储的弹性:内存与磁盘的自动切换;容错的弹性:数据丢失可以自动恢复;计算的弹性:计算出错重试机制;分片的弹性:可根据需要重新分片分布式:数据存储在大数据集群不同节点上数据集:RDD封装了计算逻辑,并不保存数据数据抽象:RDD是一个抽象类,需要子类具体实现不可变:RDD封装了计算逻辑,是不可以改变的,想要改变,只能产生新的RDD,在新的RD...

02. Spark Shuffle过程介绍
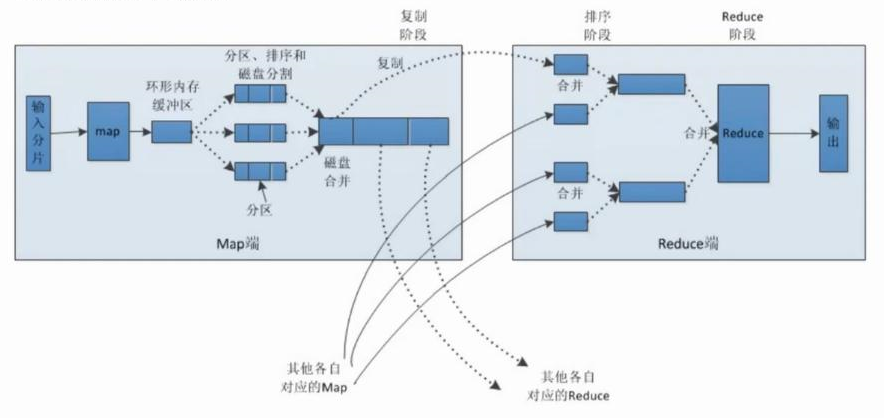
02. Spark Shuffle过程介绍一、Shuffle概念1.1 Shuffle简介有些运算需要将各节点上的同一类数据汇集到某一节点进行计算,把这些分布在不同节点的数据按照一定的规则汇集到一起的过程称为 Shuffle。1.2 MapReduce中的Shuffle在MapReduce框架,Shuffle是连接Map和Reduce之间的桥梁,Map阶段通过shuffle读取数据并输出到对应的Reduce;而Reduce阶段负责从Map端拉取数据并进行计算。在整个shuffle过程中,往往伴随着大量的磁盘和网络I/O。所以shuffle性能的高低也直接决定了整个程序的性能高低。详细过程...
01.MapReduce介绍
01.MapReduce介绍一、简介 在分布式计算中,MapReduce框架负责处理了并行编程中分布式存储、工作调度、负载均衡、容错均衡、容错处理以及网络通信等复杂问题,把处理过程高度抽象为两个函数:map和reduce。 MapReduce采用"分而治之"的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。总结:MapReduce就是"任务的分解与结果的汇总"二、Map和Reduce2.1 概念介绍MapReduce 方法使用了拆分的思想,合并了map(映射)和reduce(归约)两种...

03.Livy中REST API使用
03.Livy中REST API使用前言Livy官网REST API地址:https://livy.incubator.apache.org/docs/latest/rest-api.html官网有详细的REST API介绍一、Session操作使用RestAPI的session接口提交代码段方式运行1.1 Session操作接口1. 查询所有活跃的session信息http://127.0.0.1:8998/sessions请求方式GET请求参数参数类型描述fromint获取session的起始位置sizeint获取session数量如果都为空默认查询所有sessions会话响应参数参...

02.Livy安装教程
02.Livy安装教程一、下载1. 命令下载wget https://www.apache.org/dyn/closer.lua/incubator/livy/0.7.1-incubating/apache-livy-0.7.1-incubating-bin.zip2. 官网下载地址:http://livy.incubator.apache.org/download/二、安装1. 上传到服务器上,并解压到安装目录[root@192 root]#unzip apache-livy-0.7.1-incubating-bin.zip -d /opt/software/2. 修改livy.con...
01.Livy工作原理简介
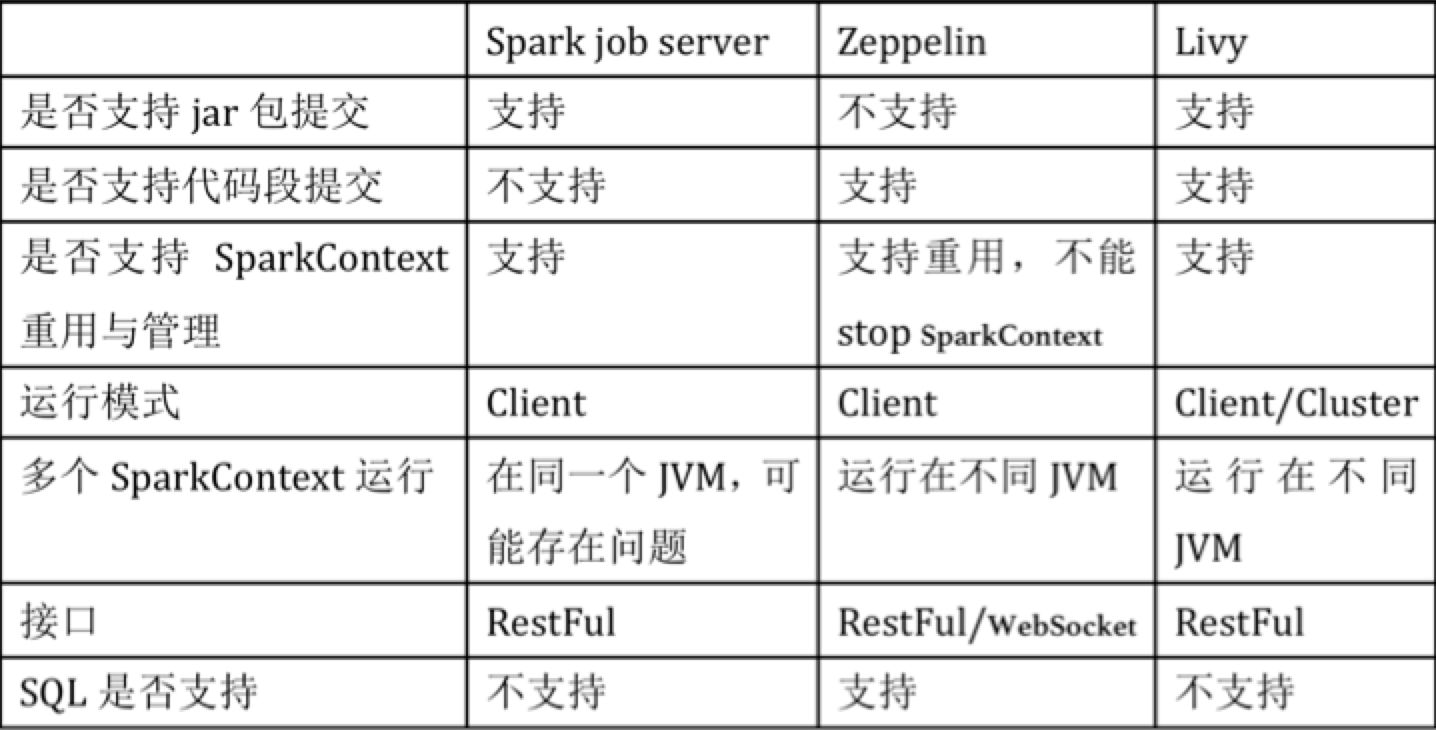
01.Livy工作原理简介前言Livy官网地址:https://livy.incubator.apache.org/一、概念介绍Livy是Apache的开源项目,目前仍然处于孵化阶段。它提供了一种通过restful接口执行交互式spark任务的机制。通过它可以进一步开发交互式的应用。当然,交互式spark应用其实有许多实现。二、功能介绍拥有长期运行的Spark Contexts供多用户提交各种的Spark job;不同的任务和用户可以共享cached RDD或者DataFrames;多个SC可以按计划同时运行,为了使得SC具有更好的容错性和并发性,可以将SC运行在yarn/Mesos等集...

复制菜单树形结构信息
复制菜单树形结构信息需求描述通过分组菜单对某一项进行复制操作,最后生成一个结构和序号完全一样的新树形分组。代码实体类Grouppublic class Group { private String id; private String name; private String parentId; private Integer order; private List<Group> child; public Group(String id, String name, String parentId, Integer order...
三、Stream流分组操作
03.Stream流分组操作前言groupingBy()是Stream API中最强大的收集器Collector之一,提供与SQL的GROUP BY子句类似的功能。一、Stream流-分组操作groupingBy(Function)一个参数:一个分组器,使用提供的字段对集合元素进行分组,返回一个Map<字段,相同字段值的元素集>groupingBy(Function,Collector)两个参数:一个是分组器,按提供的字段进行分组,一个收集器groupingBy(Function,Supplier,Collector)三个参数:一个分组器,一个最终类型的生产者,一个收集器二、...

二、Stream流操作API
02.Stream流操作API前言在学习时,可以把Stream当成一个高级版本的Iterator。原始版的Iterator,用户只能一个一个的遍历元素并对其执行某些操作;高级版本的Stream,用户只要给出需要对其包含的元素执行什么操作,具体这些操作如何应用到每个元素上,就给Stream就好了!一、通用语法1.1 示例获取一个List中,元素不为空的个数。//Lists是Guava中的一个工具类 List<Integer> nums = Lists.newArrayList(1,null,3,4,null,6); nums.stream().filter(num -> ...
一、Stream流概念介绍
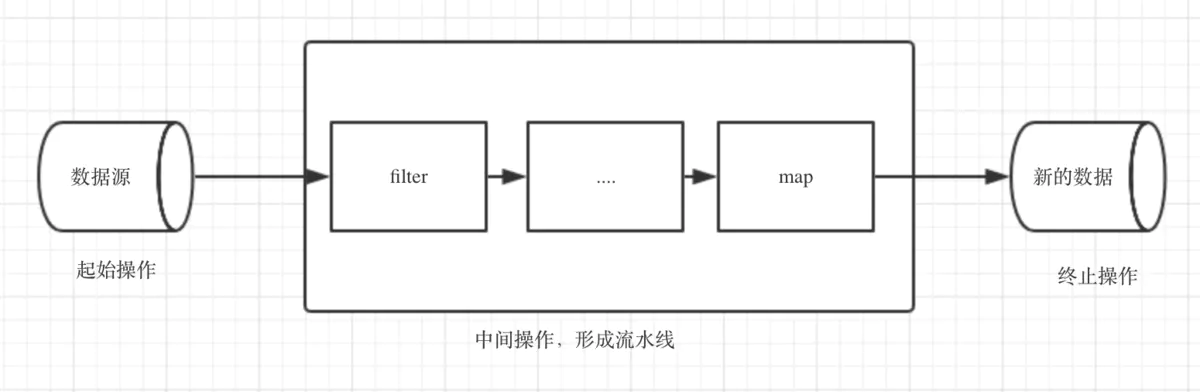
01.Stream流概念介绍前言题外话,如果看过之前推送的Scala教程或者学习过Lambda 表达式,学习Stream流将变的异常简单。一、Stream流概述Stream流中的【流】即流水线,不是I/O流。1.1 概念介绍Stream API借助于同样新出现的Lambda 表达式, 极大的提高编程效率和程序可读性.Stream 提供串行和并行两种模式进行汇聚操作, 并发模式能够充分利用多核处理器的优势, 使用fork/join 并行来拆分任务和加速处理过程.1.2 作用Java 8 中的Stream是对集合 (Collection) 对象功能的增强, 他专注于对集合对象进行各种非常便利...