
23.Flink之Watermark使用详解
[TOC]前言版本:Flink 1.10.1示例数据sensor_1,1547718199,35.8 sensor_6,1547718201,15.4 sensor_7,1547718202,6.7 sensor_10,1547718205,38.1 sensor_1,1547718206,32 sensor_1,1547718208,36.2 sensor_1,1547718210,29.7 sensor_1,1547718213,30.9 sensor_1,1547718215,32.9 sensor_1,1547718218,31.8 sensor_1,1547718225,37....

22.Flink之Watermark基本概念
[TOC]一、乱序数据的影响我们知道,流处理从事件产生,到流经source,再到operator,中间是有一个过程和时间的,虽然大部分情况下,流到operator的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络、分布式等原因,导致乱序的产生,所谓乱序,就是指 Flink 接收到的事件的先后顺序不是严格按照事件的Event Time顺序排列的。那么此时出现一个问题,一旦出现乱序,如果只根据eventTime决定window的运行,我们不能明确数据是否全部到位,但又不能无限期的等下去,此时必须要有个机制来保证一个特定的时间后,必须触发window去进行计算了,这个特别的机制,就是W...
21.Flink中的时间语义
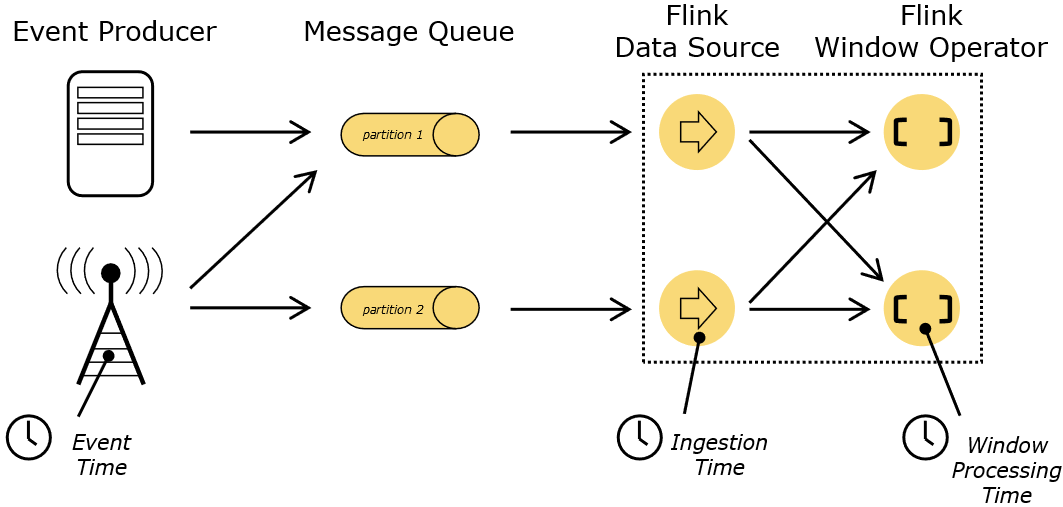
[TOC]前言在流处理中,时间是一个非常核心的概念,是整个系统的基石。我们经常会遇到这样的需求:给定一个时间窗口,比如一个小时,统计时间窗口内的数据指标。那如何界定哪些数据将进入这个窗口呢?在窗口的定义之前,首先需要确定一个作业使用什么样的时间语义。本节将介绍Flink的Event Time、Processing Time和Ingestion Time三种时间语义。一、概念在Flink的流式处理中,会涉及到时间的不同概念,如下图所示:说明上图描述了用户或者上游系统产生事件,通过发送消息这样的方式,经由消息队列传输到flink集群里进行处理的过程。Event Time(事件时间):是事件创...
20. Flink增量聚合函数和全窗口函数示例
[TOC]一、概念window function 定义了要对窗口中收集的数据做的计算操作,主要可以分为两类:增量聚合函数(incremental aggregation functions)每条数据到来就进行计算,保持一个简单的状态。典型的增量聚合函数有 ReduceFunction, AggregateFunction。全窗口函数(full window functions)先把窗口所有数据收集起来,等到计算的时候会遍历所有数据。 ProcessWindowFunction 就是一个全窗口函数。二、比较增量聚合函数计算性能较高,占用存储空间少,主要因为中间状态的计算结果,窗口中只维护中...
19.Flink Window API使用详解
[TOC]前言使用版本Flink 1.10.1JDK 1.8数据准备sensor_1,1547718199,35.8 sensor_6,1547718201,15.4 sensor_7,1547718202,6.7 sensor_10,1547718205,38.1 sensor_1,1547718206,32 sensor_1,1547718208,36.2 sensor_1,1547718210,29.7 sensor_1,1547718213,30.9nc工具命令nc -lk 8888一、窗口适配器(window assigner)1.1 概述窗口分配器:window() 方法我们...
18.Flink window API介绍
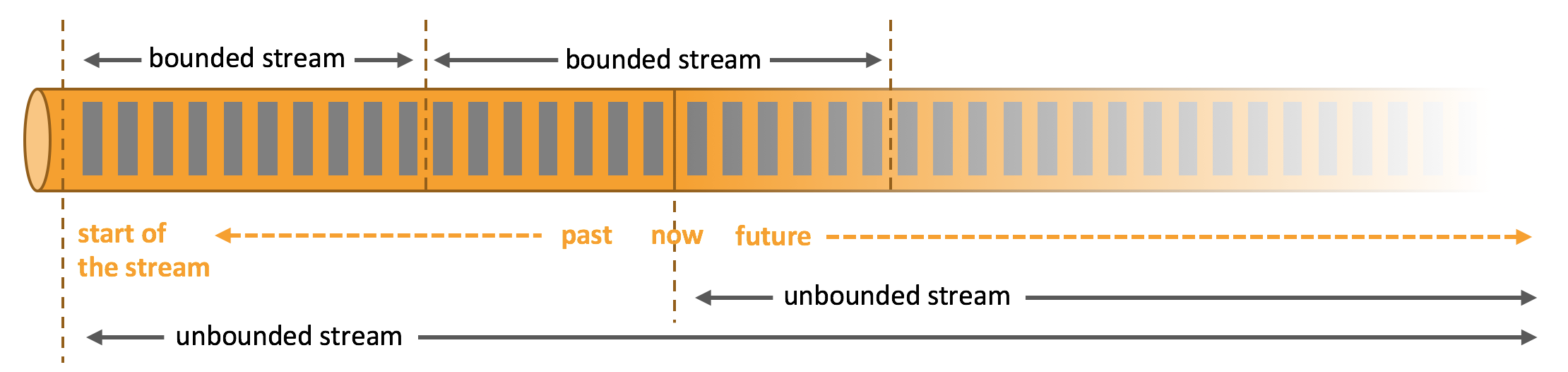
[TOC]一、窗口(window) 概念streaming流式计算是一种被设计用于处理无限数据集的数据处理引擎无限数据集是指一种不断增长的本质上无限的数据集窗口(window)是一种切割无限数据为有限块进行处理的手段Window是无限数据流处理的核心,Window将一个无限的stream拆分成有限大小的”buckets”桶,我们可以在这些桶上做计算操作Flink认为Batch是Streaming的一个特例,所以Flink底层引擎是一个流式引擎,在上面实现了流处理和批处理。窗口(window)就是从 Streaming 到 Batch 的一个桥梁场景示例 当然我们可以每来一...

17.Flink流处理API之Sink
[TOC]前言使用 Flink 进行数据处理时,数据经 Data Source 流入,通过系列 Transformations 的转化,最终可以通过 Sink 将计算结果进行输出,Flink Data Sinks 就是用于定义数据流最终的输出位置。一、概述Flink没有类似于spark中foreach方法,让用户进行迭代的操作。虽有对外的输出操作都要利用Sink完成。最后通过类似如下方式完成整个任务最终输出操作。stream.addSink(new MySink(xxxx))官方提供了一部分的框架的sink。除此以外,需要用户自定义实现sink。二、输出到文件import org.apa...

16.Flink实现UDF函数
前言实现UDF的目的是为了更加细粒度的控制流。一、函数类(Function Classes)Flink暴露了所有UDF函数的接口(实现方式为接口或者抽象类)。例如MapFunction, FilterFunction, ProcessFunction等等。下面例子实现了FilterFunction接口://自定义函数类,筛选出成绩大于等于60的学生 class MyFilter extends FilterFunction[Student]{ override def filter(t: Student): Boolean = { t.score >= 60 } }...
15【转载】Flink数据类型和序列化
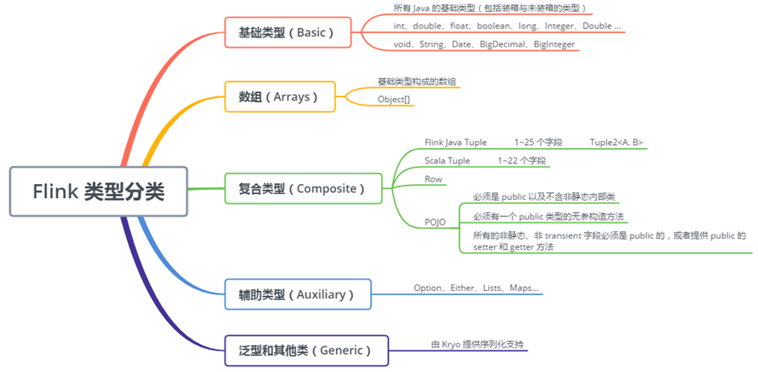
[TOC]一、为 Flink 量身定制的序列化框架为什么要为 Flink 量身定制序列化框架? 大家都知道现在大数据生态非常火,大多数技术组件都是运行在 JVM 上的,Flink 也是运行在 JVM 上,基于 JVM 的数据分析引擎都需要将大量的数据存储在内存中,这就不得不面临 JVM 的一些问题,比如 Java 对象存储密度较低等。 针对这些问题,最常用的方法就是实现一个显式的内存管理,也就是说用自定义的内存池来进行内存的分配回收,接着将序列化后的对象存储到内存块中。 现在 Java 生态圈中已经有许多序列化框架,比如说 Java serializat...

14.Flink流处理API之Transform转换算子
[TOC]1、Map作用将数据流中的数据进行转换, 形成新的数据流,消费一个元素并产出一个元素。示例需求:使用Map将数据转换成样例类代码import org.apache.flink.streaming.api.scala._ /** * Created by lilinchao * Date 2022/1/13 * Description 使用Map将数据转换成样例类 */ object StreamMapTest { def main(args: Array[String]): Unit = { //1.构建运行环境 val env = St...