李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
【转载】Elastic Stack之Data Stream的概念
Leefs
2021-12-27 PM
1113℃
0条
[TOC] ### 时序性数据 时间序列数据( time series data )是在不同时间上收集到的数据,用于所描述现象随时间变化的情况。这类数据反映了某一事物、现象等,随时间的变化状态或程度。 总的来说,这类数据主要基于时间特性明显,随着时间的流逝,往往过去时间的数据没有现在时间的重要或者敏感。 对于 Elastisearch 处理时序性数据,有人总结了主要有以下特点: - 由时间戳 + 数据组成。基于时间的事件,可以是服务器日志或者社交媒体流。 - 通常搜索最近事件,旧文件变得不太重要。 - 索引的使用主要基于时间,但是数据并不一定随着时间均衡分布。 - 时序性数据一旦存入后很少修改。 - 时序性数据随着时间的增加,数据量会很大。 Elastisearch 在时序性数据的使用中,往往会有以下的缺点: - 索引随着时间增加而数目较多。 - 索引大小无法均衡。 - 管理索引成本较高,需要维护 merge 合并删除等一系列任务。 - 节点资源与冷热数据分布不匹配。 在这样的一个场景下,数据流 Data stream 应运而生。 Data stream (数据流)是 Elastic Stack 7.9 的一个新的功能。Data stream 可以跨多个索引存储只追加时序性数据,同时为查询写入等请求提供唯一的一个命名资源。Data stream 非常适合日志,事件,指标以及其他持续生成的数据。 简单来说,Data stream 根据模板生成存储数据的后备索引,然后自动将搜索或者索引请求路由到存储流数据的后备索引。而这些后备索引则根据索引生命周期管理( ILM )来自动管理。 例如,你可以使用 ILM 自动将较旧的后备索引移动到较便宜的硬件上(冷热数据处理),根据索引大小自动 Rollover 出新的后备索引,或者删除到时间限制的索引。 在一定程度上,Data stream 的管理优势是利用了 ILM 的特性。但是 ILM 在普通场景下需要根据索引的别名( alias )逐个设置,而 Data stream 则是抛弃了 alias 的限制,可以直接批量化设置相似名称的索引,大大增加了 ILM 的使用范围。 ### Data stream 的组成 数据流在 Elasticsearch 集群中由一个或多个隐藏的、自动生成的后备索引组成。 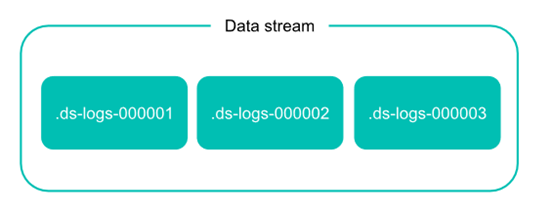 在实际的 Elasticsearch 操作中,数据流依靠索引模板来设定数据流实体的后备索引。 - 模板包含用于配置流的后备索引的映射和设置。 - 同一个索引模板可用于多个数据流。 - 不能删除数据流正在使用的索引模板。 每个索引到数据流的文档,必须包含一个 @timestamp 字段,映射为 date 或 date_nanos 字段类型。如果索引模板没有为 @timestamp 字段指定映射,Elasticsearch 将 @timestamp 映射为带有默认选项的日期字段。 Data stream 的读请求主要如下图,数据流自动将请求路由到其所有后备索引。  而对于写请求,数据流则将该请求自动转发给最新的后备索引。  对于写请求,有两点需要注意: - 不能将新文档添加到其他非最新后备索引,即使直接将请求发送到这些索引也不行。 - 不能对正在写入的索引做 Clone/Close/Delete/Freeze/Shrink/Split 相关操作。 > 注:7.12版本可以 Close ### Data stream 的特性 #### 生成 每个 Data stream 的后备索引都有一个 generation 数,一个六位数,零填充的整数,从 000001 开始,用作该流的 rollover 的计数。 后备索引名主要依照以下格式: .ds-- Generation 越大,后备索引包含的数据越新。 例如,web-server-logs 数据流最新的 generation 为 34。该流的最新后备索引名为 .ds-web-server-logs-000034。 注意:某些操作(例如 shrink 或 restore )可以更改后备索引的名称。 这些名称更改不会从其数据流中删除后备索引。 #### Rollover 在 Data stream 的使用中,rollover 是必不可少的条件。 创建数据流时,Elasticsearch 会自动为该 Data stream 根据 template 创建一个后备索引。 该索引还充当流的第一个写入索引。当满足一定条件时, rollover 会创建一个新的后备索引,该后备索引将成为 Data stream 的新写入索引。 当然 rollover 的条件设置主要依靠 ILM。 如果需要,你还可以手动将数据 rollover 。 #### 追加 由于时序性数据的特征,Data stream 的设计场景中,数据是只追加的,极少需要修改删除。如果实际需要修改删除,则可以考虑以下操作: - 对于数据流只能通过 update by query 或者 delete by query 操作,不能进行 update 或者 delete 文档。 - 需要 delete 或者 update 文档,则直接对后备索引操作。 - 需要经常删除或者修改文档的,请使用索引别名或者索引模板,不要对 Data stream 操作。 ### Data stream 的使用 #### 创建索引生命周期管理策略 ILM 索引生命周期管理策略 ILM 的主要配置细节见索引周期管理一章,此处主要做 hot 和 delete 阶段的设置,用于 rollover 的引用。 相关命令: ```json PUT /_ilm/policy/my-data-stream-policy { "policy": { "phases": { "hot": { "actions": { "rollover": { "max_size": "25GB" } } }, "delete": { "min_age": "30d", "actions": { "delete": {} } } } } } ``` Kibana 图形界面: Stack Management -> Index Lifecycle Policies -> Create policy   注意: 1. rollover 设置中,文档数和最大存在时间是相对敏感的配置参数,由于 Elasticsearch 并不是实时监控 ILM 的执行任务(默认十分钟),最终结果并不一定完全一致。 2. ILM 任务判断中,max_size 判断的是主分片的大小,而不是整个索引的大小。 3. 新版本下,max_size 的判断并不敏感,可能是因为索引的主分片 size 大小会被 merge 后收缩,需要有一定时间的观察。如下图。测试之下,200MB之下的 max_size 会失效。建议 max_size 设置参数不要太小。  #### 创建索引模板 索引模板是后备索引设置,以及 mapping 的主要配置来源,此处不展开延伸。主要设置 Data stream 相关的部分。 相关命令: ```json PUT /_index_template/my-data-stream-template { "index_patterns": [ "my-data-stream*" ], "data_stream": { }, "priority": 200, "template": { "settings": { "index.lifecycle.name": "my-data-stream-policy" } } } ``` 注意: 1. 定义 data_stream 为一个空的 object ,这是必要的。 2. Template 中使用了上一步创建的 ILM 策略 my-data-stream-policy。 此外,还需要注意两点: 1. Elasticsearch 有一些内置索引模板如 metric-**-** 和 logs-**-** ,默认优先级 priority 是 100。如果有重名使用,则可以调高优先级,防止被默认的覆盖。 2. 索引模板默认将 @timestamp 字段设置为 date 属性。 Kibana 界面: Stack Management -> Index Management -> Index Templates -> Create template 创建 template,不要创建旧版索引,并打开数据流标签  设置生命周期管理策略,其他设置此处省略,一直下一步至创建完成。  #### 创建 Data stream 可以自动利用 template 的匹配模式新增文档创建: ```json POST /my-data-stream/_doc/ { "@timestamp": "2020-12-06T11:04:05.000Z", "user": { "id": "vlb44hny" }, "message": "Login attempt failed" } ``` Response: ```json { "_index" : ".ds-my-data-stream-000001", "_type" : "_doc", "_id" : "8ZadZXkBkhA9X9yUbI17", "_version" : 1, "result" : "created", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 0, "_primary_term" : 1 } ``` 也可以直接 PUT 创建一个空的 Data stream。 ```http PUT /_data_stream/my-data-stream ``` #### 删除 删除命令: ```http DELETE /_data_stream/my-data-stream ``` 删除数据流会将数据流的后备索引一起删除。 ### 使用 Data stream 此处对数据流的操作主要以命令为主,Kibana 界面支持较少。 #### 新增数据 Data stream 在新增数据时是只追加的模式,因此在固定 id 和 bulk 的模式下,op_type 是指定 create 的。 如下面命令: ```json POST my-data-stream/_create/1 {"@timestamp":"2020-12-07T11:06:07.000Z","test":1} ``` 或者 ```json PUT /my-data-stream/_bulk?refresh {"create":{ }} { "@timestamp": "2020-12-08T11:04:05.000Z", "user": { "id": "vlb44hny" }, "message": "Login attempt failed" } {"create":{ }} { "@timestamp": "2020-12-08T11:06:07.000Z", "user": { "id": "8a4f500d" }, "message": "Login successful" } {"create":{ }} { "@timestamp": "2020-12-09T11:07:08.000Z", "user": { "id": "l7gk7f82" }, "message": "Logout successful" } ``` 如果并不指定,文档的 id,则可以使用默认的 _doc ,如下: ```json POST my-data-stream/_doc/ {"@timestamp":"2020-12-07T11:06:07.000Z","test":1} ``` #### 获取 Data stream 状态 使用 Data stream stats API 查看 Data stream 的状态。 ```json GET /_data_stream/my-data-stream/_stats?human=true ``` Response: ```json { "_shards" : { "total" : 4, "successful" : 2, "failed" : 0 }, "data_stream_count" : 1, "backing_indices" : 1, "total_store_size" : "5kb", "total_store_size_bytes" : 5151, "data_streams" : [ { "data_stream" : "my-data-stream", "backing_indices" : 1, "store_size" : "5kb", "store_size_bytes" : 5151, "maximum_timestamp" : 1607252645000 } ] } ``` 可见 my-data-stream 的大下和后备索引数量。 同时需要用 _ilm/explain 获取 Data stream 后备索引所在的 ILM 策略状态。 ```json GET my-data-stream/_ilm/explain ``` Response: ```json { "indices" : { ".ds-my-data-stream-000001" : { "index" : ".ds-my-data-stream-000001", "managed" : true, "policy" : "my-data-stream-policy", "lifecycle_date_millis" : 1620907943375, "age" : "7.95s", "phase" : "hot", "phase_time_millis" : 1620907943567, "action" : "rollover", "action_time_millis" : 1620907943661, "step" : "check-rollover-ready", "step_time_millis" : 1620907943661, "phase_execution" : { "policy" : "my-data-stream-policy", "phase_definition" : { "min_age" : "0ms", "actions" : { "rollover" : { "max_size" : "25gb" } } }, "version" : 1, "modified_date_in_millis" : 1620907939978 } } } } ``` 上图可见,这个数据的 000001 索引主要处于 hot 阶段,策略名称是 logs 等信息。具体参数可见于 ILM 的相关定义。 #### 手动 rollover Data stream 使用 rollover API,手动 rollover Data stream。 ```http POST my-data-stream/_rollover ``` Response: ```json { "acknowledged" : true, "shards_acknowledged" : true, "old_index" : ".ds-my-data-stream-000001", "new_index" : ".ds-my-data-stream-000002", "rolled_over" : true, "dry_run" : false, "conditions" : { } } ``` 再 GET 相关 Data stream 状态,后备索引增加。 ```http GET /_data_stream/my-data-stream/ ``` Response: ```json { "data_streams" : [ { "name" : "my-data-stream", "timestamp_field" : { "name" : "@timestamp" }, "indices" : [ { "index_name" : ".ds-my-data-stream-000001", "index_uuid" : "AJBi0g3fRyG8-1tiH2UD2Q" }, { "index_name" : ".ds-my-data-stream-000002", "index_uuid" : "AgOLGMSBSYWb4X-ID8uwtg" } ], "generation" : 2, "status" : "GREEN", "template" : "my-data-stream-template", "ilm_policy" : "my-data-stream-policy", "hidden" : false } ] } ``` #### Reindex Data stream 使用 reindex API 去复制数据到一个 Data stream。由于 Data stream 的只追加特性,在 op_type 中要选择为 create 。 ```json POST /_reindex { "source": { "index": "test" }, "dest": { "index": "my-data-stream", "op_type": "create" } } ``` Response: ```json { "took" : 80, "timed_out" : false, "total" : 1, "updated" : 0, "created" : 1, "deleted" : 0, "batches" : 1, "version_conflicts" : 0, "noops" : 0, "retries" : { "bulk" : 0, "search" : 0 }, "throttled_millis" : 0, "requests_per_second" : -1.0, "throttled_until_millis" : 0, "failures" : [ ] } ``` #### Delete/Update by query 针对 Data stream 只能 delete/update by query 。 相关命令: ```json POST /my-data-stream/_update_by_query { "query": { "match": { "user.id": "l7gk7f82" } }, "script": { "source": "ctx._source.user.id = params.new_id", "params": { "new_id": "XgdX0NoX" } } } POST /my-data-stream/_delete_by_query { "query": { "match": { "user.id": "vlb44hny" } } } ``` #### Delete update 后备索引数据 在后备索引删除或者修改,需要注意下面三个要素: - 文档 id。 - 文档所在的后备索引。 - 如果是修改文档,则需要其 _seq_no 和 _primary_term 两个参数。 主要操作如下: 先获取文档所需的要素信息,设置 seq_no_primary_term 为 true。 ```json GET /my-data-stream/_search { "seq_no_primary_term": true, "query": { "match": { "message": "Login attempt failed" } } } ``` 获得结果: ```json { "took" : 621, "timed_out" : false, "_shards" : { "total" : 2, "successful" : 2, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1, "relation" : "eq" }, "max_score" : 0.8630463, "hits" : [ { "_index" : ".ds-my-data-stream-000001", "_type" : "_doc", "_id" : "9ZakZXkBkhA9X9yUZo2P", "_seq_no" : 0, "_primary_term" : 1, "_score" : 0.8630463, "_source" : { "@timestamp" : "2020-12-06T11:04:05.000Z", "user" : { "id" : "vlb44hny" }, "message" : "Login attempt failed" } } ] } } ``` 然后修改命令: ```json PUT /.ds-my-data-stream-000001/_doc/9ZakZXkBkhA9X9yUZo2P?if_seq_no=0&if_primary_term=1 { "@timestamp": "2020-12-07T11:06:07.000Z", "test": 4 } ``` Response: ```json { "_index" : ".ds-my-data-stream-000001", "_type" : "_doc", "_id" : "9ZakZXkBkhA9X9yUZo2P", "_version" : 2, "result" : "updated", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 1, "_primary_term" : 1 } ``` 或者删除命令: ```json DELETE /.ds-logs-1-1-000002/_doc/3 ``` #### 关于修改 Data stream 的 mapping 和 setting Data stream 的 setting 和 mapping 修改主要还是基于 Elasticsearch 默认的修改规则。总结一下,主要有以下几点: - 新增字段不影响。 - 已存在的配置不可更改。 - 修改的 template 只能应用于未来新增的索引。 因此,如果需要修改不可更改的配置,可以考虑 reindex 或者修改 template 后手工 Rollover Data stream。 ### 关于 Data tiers Data tiers 也称数据层,是一个在 7.10 版本的一个新概念。 Data tiers 主要的一个特点是将节点角色( node roles )与索引生命周期所需要的节点属性( attribute )结合,直接可以在制定 Elasticsearch 节点角色时配置,不需要再去设置 attribute 。Data tiers 的概念也是对时序性数据分层管理的优化配置。 Data tiers 的数据节点默认是都配置的,即 data_content/data_hot/data_warm/data_cold( chsw )都具备。 #### Tiers 的定义 - **Content tier** Content tier 节点存储的数据,往往定义为与时序性数据相反的常态化数据,比如商品种类这种随着时间推移保持相对不变。这种数据并不能根据冷热数据性质分层存储。 此类数据有以下特点: ``` - Content tier 节点通常需要较高的计算性能,要求处理能力比 IO 吞吐能力高,需要处理复杂的搜索和聚合并快速返回结果。 - 对数据内容的获取,即文档内容本身获取比时序性数据要少。 - 这类数据索引需要配置为一个或多个副本。 ``` - **Hot tier** Hot tier,热层是时间序列数据的 Elasticsearch 入口点,最新存储的时间序列数据。Hot tier 的数据也是会被查询最多的数据。因此热层中的节点在读取和写入时都需要快速,这需要更多的硬件资源和更快的存储( SSD)。属于数据流 ( Data stream )的新索引会自动分配给热层。 - **Warm tier** 即温层,一旦查询时间序列数据的频率低于 hot tier 中最近索引的数据,便可以将其移至 warm tier 。 warm tier 通常保存最近几周的数据。 仍然允许进行更新,但可能很少。通常,warm tier 中的节点不需要像 hot tier 中的节点一样快。 - **Cold tier** 冷层的数据一般查询频率非常低,且不会被更新。 但是 cold tier 仍然是响应查询层。 随着数据过渡到 cold tier,可以对其进行压缩和去副本。Cold tier节点的机器配置可以相对较低。 #### tier_preference index.routing.allocation.include._tier_preference 是 Data tiers 的主要配置方式,在分片数据的时候使用 tier_preference 指定数据节点的分配。 tier_preference 的设置会有三种情况: 1. 创建正常索引时,默认情况下,Elasticsearch 将 index.routing.allocation.include._tier_preference 设置为 data_content ,以将索引分片自动分配给内容层。 2. 创建数据流时,Elasticsearch 会将后备索引的 index.routing.allocation.include._tier_preference 设置为 data_hot,以自动将索引分片分配给热层。 3. 显式设置 index.routing.allocation.include._tier_preference,选择索引需要的数据节点。 如果将层首选项设置为 null,则 Elasticsearch 在分配期间将忽略数据层角色,依照其它参数分配。 相关的图形和命令配置如下:  上图时在索引生命周期管理中选择 Data tiers节点。 ```json PUT _index_template/template_demo { "index_patterns": ["demo-*"], "data_stream": {}, "priority": 200, "template": { "settings": { "number_of_shards": 2, "index.lifecycle.name": "demo", "index.routing.allocation.include._tier_preference": "data_hot" } } } ``` 上面命令中设置索引模板匹配 demo-* 的索引的分配策略为 "index.routing.allocation.include._tier_preference":"data_hot" *附原文链接地址:* *https://developer.aliyun.com/article/784131#slide-15*
标签:
Elastisearch
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://www.lilinchao.com/archives/1800.html
上一篇
Elasticsearch索引生命周期管理
下一篇
07.Flink运行时组件
取消回复
评论啦~
提交评论
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
标签云
Spark Core
队列
栈
ClickHouse
随笔
SpringCloudAlibaba
Redis
Hive
MySQL
Kafka
排序
Java阻塞队列
Ubuntu
持有对象
数据结构
Typora
JavaScript
锁
nginx
查找
Yarn
链表
算法
Elastisearch
Flink
Docker
Netty
Spark RDD
Git
字符串
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞