李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
06.Flink Yarn模式介绍
Leefs
2021-12-24 AM
1432℃
0条
[TOC] ### 前言 Flink的Standalone和on Yarn模式都属于集群运行模式,但是有很大的不同,在实际环境中,使用Flink on Yarn模式者居多。 **Standalone和on Yarn模式的最大不同点是管理资源的不同:** + Standalone模式通过Flink自身来管理集群资源 + on Yarn模式通过Hadoop Yarn来对集群资源进行管理 ### 一、概述 以Yarn模式部署Flink任务时,要求Flink是有Hadoop支持的版本,Hadoop环境需要保证版本在 2.2以上,并且集群中安装有HDFS服务。 #### Flink on Yarn Flink提供了两种在yarn上运行的模式,分别为**Session-Cluster**和**Per-Job-Cluster**模式。 + **Session-cluster模式** 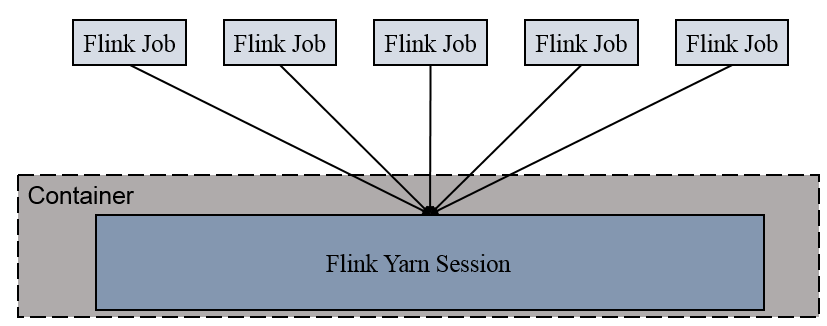 Session-Cluster模式需要先启动集群,然后再提交作业,接着会向yarn申请一块空间后,资源永远保持不变。如果资源满了,下一个作业就无法提交,只能等到yarn中的其中一个作业执行完成后,释放了资源,下个作业才会正常提交。所有作业共享Dispatcher和ResourceManager;共享资源;适合规模小执行时间短的作业。 在yarn中初始化一个flink集群,开辟指定的资源,以后提交任务都向这里提交。这个flink集群会常驻在yarn集群中,除非手工停止。 + **Per-Job-Cluster模式**  一个Job会对应一个集群,每提交一个作业会根据自身的情况,都会单独向yarn申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行。独享Dispatcher和 ResourceManager,按需接受资源申请;适合规模大长时间运行的作业。 每次提交都会创建一个新的flink集群,任务之间互相独立,互不影响,方便管理。任务执行完成之后创建的集群也会消失。 ### 二、执行命令 + **Session Cluster** **(1)启动yarn-session** ```shell [root@hadoop001 bin]# pwd /opt/software/flink-1.14.2/bin [root@hadoop001 bin]# ./yarn-session.sh -n 2 -s 2 -jm 1024 -tm 1024 -nm test -d ``` **说明** | 参数 | 说明 | | --------------- | ------------------------------------------------------------ | | -n(--container) | TaskManager 的数量 | | -s(--slots) | 每个 TaskManager 的 slot 数量,默认一个 slot 一个 core,默认每个 taskmanager 的 slot 的个数为 1,有时可以多一些 taskmanager,做冗余。 | | -jm | JobManager 的内存(单位 MB) | | -tm | 每个 taskmanager 的内存(单位MB) | | -nm | yarn 的 appName(现在 yarn 的 ui 上的名字) | | -d | 后台执行 | **(2)执行任务** ```shell [root@hadoop001 bin]# ./flink run -c com.leefs.wc.StreamWordCount flinkdemo.jar --host lcoalhost –port 7777 ``` **(3)通过yarn控制台查看任务状态** **(4)取消yarn-session** ```shell yarn application --kill application_1577588252906_0001 ``` + **Per Job Cluster** **(1)执行任务** ```shell [root@hadoop001 bin]# ./flink run –m yarn-cluster -c com.leefs.wc.StreamWordCount flinkdemo.jar --host lcoalhost –port 7777 ``` *注意:不启动 yarn-session,直接执行 job* ### 三、Yarn高可用和Standalone 高可用区别 + **Standalone 高可用** 同时启动多个JobManger,若执行任务的JobManger挂了,其他JobManager马上补上。 + **Yarn 高可用** JobManager只有一个,但是配置了重试次数,挂了之后再重启(重启一个新的ApplicationManager),利用了ApplicationMaster的重启机制。 若在一定时间范围内重试都启动不了,那么就真的挂了。 如30秒内重试3次,若重启成功,则重试次数清零。 ### 总结 **Flink提供在Yarn上两种运行模式:Session-Cluster和Per-Job-Cluster** Session-Cluster:资源在启动集群时就定义完成,后续所有作业的提交都共享该资源,作业可能会互相影响,因 此比较适合小规模短时间运行的作业; Per-Job-Cluster:所有作业的提交都是单独的集群,作业之间的运行不受影响(可能会共享CPU计算资源),因此 比较适合大规模长时间运行的作业。 *附参考文章链接:* *https://www.jianshu.com/p/861bc86465c9*
标签:
Flink
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://www.lilinchao.com/archives/1783.html
上一篇
05.Flink Standalone模式单机版安装
下一篇
Cerebro安装教程
取消回复
评论啦~
提交评论
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
标签云
RSA加解密
Flink
Livy
容器深入研究
SQL练习题
并发编程
数据结构
微服务
字符串
链表
JavaScript
Golang基础
Sentinel
Kafka
数学
机器学习
Golang
国产数据库改造
Spark
VUE
Jquery
SpringCloud
Flume
Map
Thymeleaf
正则表达式
Linux
Stream流
Spark Streaming
Python
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞