李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
02.DStream入门
Leefs
2021-10-19 PM
996℃
0条
[TOC] ### 前言 本篇将通过一个WordCount案例来作为DStream的入门。 ### 一、环境 #### 1.1 所需运行环境 | IP | 作用 | 系统 | | ------------------ | ---------------------------------------- | ------- | | 192.168.10.2(本机) | 运行案例代码接收服务端9999端口发送的信息 | windows | | 192.168.10.7 | 运行netcat监听9999端口 | Linux | #### 1.2 netcat工具介绍和安装 ##### **介绍** netcat简称nc,netcat是网络工具中的瑞士军刀,它能通过TCP和UDP在网络中读写数据,通过与其它工具结合和重定向,你可以在脚本中以多种方式使用它。 ##### 基本功能 - telnet / 获取系统 banner 信息 - 传输文本信息 - 传输文件和目录 - 加密传输文件 - 端口扫描 - 远程控制 / 正方向 shell - 流媒体服务器 - 远程克隆硬盘 ##### 安装 执行如下命令可直接在CentOS服务器上直接进行安装 ``` yum install -y nc ``` ##### 命令 nc 可以在两台机器之间相互传递信息,首先需要有一台机器进行监听一个端口,另一台以连接的方式去连接其指定的端口,这样两台机器之间建立了通信后,相互之间可以传输信息。 + -l 开启监听模式,用于指定nc将处于监听模式。通常这样代表着为一个服务等待客户端来链接指定的端口。 + -p<通信端口> 设置本地主机使用的通信端口。有可能会关闭 + -k<通信端口>强制 nc 待命链接.当客户端从服务端断开连接后,过一段时间服务端也会停止监听。 但通过选项 -k 我们可以强制服务器保持连接并继续监听端口。 (更多命令和使用方法本篇将不在赘述,如果想了解更深可以自行查阅相关资料) ### 二、WordCount案例实操 #### 2.1 需求 > 使用netcat工具向9999端口不断的发送数据,通过SparkStreaming读取端口数据并统计不同单词出现的次数 #### 2.2 操作步骤 (1)添加依赖 ```xml <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.12</artifactId> <version>3.0.0</version> </dependency> ``` (2)代码实现 ```scala import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.streaming.{Seconds, StreamingContext} /** * @author lilinchao * @date 2021/8/11 * @description 1.0 **/ object SparkStreaming01_WordCount { def main(args: Array[String]): Unit = { //使用SparkStreaming完成WordCount //Sprak配置对象 val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming01_WordCount") //实时数据分析环境对象 //采集周期:以指定的时间为周期采集实时数据 val streamingContext = new StreamingContext(sparkConf,Seconds(3)) //从指定的端口采集数据 val socketLineDStream: ReceiverInputDStream[String] = streamingContext.socketTextStream("192.168.10.7", 9999) //将采集的数据进行分解(扁平化) val wordDStream: DStream[String] = socketLineDStream.flatMap(line => line.split(" ")) //将数据进行结构的转换方便统计分析 val mapDStream: DStream[(String, Int)] = wordDStream.map((_, 1)) //将转换结构后的数据进行聚合处理 val wordToSumDStream: DStream[(String, Int)] = mapDStream.reduceByKey(_ + _) //将结果 打印出来 wordToSumDStream.print() //注意:不能停止采集功能 //streamingContext.stop() //启动采集器 streamingContext.start() //Drvier等待采集器的执行: streamingContext.awaitTermination() } } ``` (3)运行netcat监听9999端口 ``` nc -lk 9999 ``` (4)启动程序 (5)netcat输入数据  (6)控制台输出结果 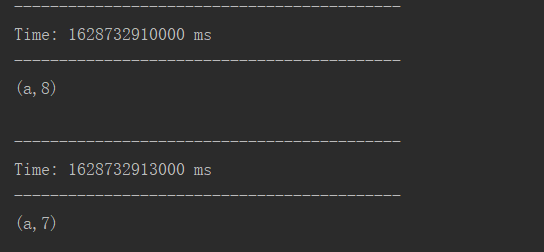 ### 三、WordCount解析 Discretized Stream是Spark Streaming的基础抽象,代表持续性的数据流和经过各种Spark原语操作后的结果数据流。在内部实现上,DStream是一系列连续的RDD来表示。每个RDD含有一段时间间隔内的数据,如下图:  对数据的操作也是按照RDD为单位来进行的  计算过程由Spark engine来完成  *附:* [参考文章链接地址](https://blog.csdn.net/qq_29499107/article/details/82384393)
标签:
Spark
,
Spark Streaming
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://www.lilinchao.com/archives/1578.html
上一篇
01.SparkStreaming概述
下一篇
03.DStream创建
取消回复
评论啦~
提交评论
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
标签云
Jquery
HDFS
并发编程
FastDFS
Yarn
ClickHouse
前端
Filter
国产数据库改造
LeetCode刷题
Docker
Hive
Azkaban
Java工具类
正则表达式
Spark
队列
Flink
查找
Golang
Flume
Python
哈希表
Map
随笔
Hbase
Quartz
Spark Core
RSA加解密
高并发
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞