李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
04.HDFS之API操作
Leefs
2021-09-16 PM
962℃
0条
[TOC] ### 前言 本次操作使用过的版本是`hadoop-client 3.1.3`,在进行操作之前,需要创建好一个Maven项目,在进行后续的操作。 ### 一、概念 Hadoop中关于文件操作类基本上全部是在"**org.apache.hadoop.fs**"包中,这些API能够支持的操作包含:打开文件,读写文件,删除文件等。 Hadoop类库中最终面向用户提供的**接口类**是**FileSystem**,该类是个**抽象类**,只能通过来类的get方法得到具体类。 ### 二、实操 #### 2.1 引入Maven依赖 ```xml <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.1.3</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>3.1.3</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs-client</artifactId> <version>3.1.3</version> <scope>provided</scope> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.30</version> </dependency> ``` #### 2.2 引入日志配置文件 **log4j.properties** ```xml log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n ``` #### 2.3 代码 ```java import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org.junit.After; import org.junit.Before; import org.junit.Test; import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; import java.util.Arrays; /** * 客户端代码常用套路 * 1、获取一个客户端对象 * 2、执行相关的操作命令 * 3、关闭资源 * HDFS zookeeper */ public class HdfsClient { private FileSystem fs; @Before public void init() throws URISyntaxException, IOException, InterruptedException { // 连接的集群地址 URI uri = new URI("hdfs://hadoop102:8020"); // 创建一个配置文件 Configuration configuration = new Configuration(); //设置副本数 configuration.set("dfs.replication", "2"); // 用户 String user = "root"; // 1 获取到了客户端对象 fs = FileSystem.get(uri, configuration, user); } @After public void close() throws IOException { // 3 关闭资源 fs.close(); } /** * 创建目录 * @throws IOException */ @Test public void testmkdir() throws IOException { // 2 创建一个文件夹 fs.mkdirs(new Path("/data/llc/demo")); } /** * 本地文件上传HDFS * 参数优先级 * hdfs-default.xml => hdfs-site.xml=> 在项目资源目录下的配置文件 =》代码里面的配置 * @throws IOException */ @Test public void testPut() throws IOException { // 参数解读:参数一:表示删除原数据; 参数二:是否允许覆盖;参数三:原数据路径; 参数四:目的地路径 fs.copyFromLocalFile(false, true, new Path("D:\\air.csv"), new Path("hdfs://hadoop102:8020/data/llc/demo")); } /** * 通过create方法上传文件 * 当文件已存在时会进行覆盖 * @throws IOException */ @Test public void testPut2() throws IOException { FSDataOutputStream fos = fs.create(new Path("/data/llc/llc.txt")); //写入文件内容 fos.write("hello world".getBytes()); } /** * 文件下载 * @throws IOException */ @Test public void testGet() throws IOException { // 参数的解读:参数一:原文件是否删除;参数二:原文件路径HDFS; 参数三:目标地址路径Win ; 参数四: // fs.copyToLocalFile(true, new Path("hdfs://hadoop102:8020/data/llc/demo/air.csv"), new Path("D:\\"), true); fs.copyToLocalFile(false, new Path("hdfs://hadoop102:8020/data/llc/llc.txt"), new Path("D:\\"), false); } /** * 删除 * @throws IOException */ @Test public void testRm() throws IOException { // 参数解读:参数1:要删除的路径; 参数2 : 是否递归删除 // 删除文件 // fs.delete(new Path("/data/llc/word.csv"),false); // 删除空目录 // fs.delete(new Path("/data/llc/demo"), false); // 删除非空目录 fs.delete(new Path("/data/llc"), true); } /** * 文件的更名和移动 * @throws IOException */ @Test public void testmv() throws IOException { // 参数解读:参数1 :原文件路径; 参数2 :目标文件路径 // 对文件名称的修改 // fs.rename(new Path("/data/input/word.csv"), new Path("/data/input/word2.csv")); // 文件的移动和更名 // fs.rename(new Path("/data/input/demo01/test.csv"),new Path("/data/input/llc.csv")); // 目录更名 fs.rename(new Path("/data/input/demo01"), new Path("/data/input/demo")); } /** * 获取文件详细信息 * @throws IOException */ @Test public void fileDetail() throws IOException { // 获取所有文件信息 RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/data/input"), true); // 遍历文件 while (listFiles.hasNext()) { LocatedFileStatus fileStatus = listFiles.next(); System.out.println("==========" + fileStatus.getPath() + "========="); System.out.println(fileStatus.getPermission()); System.out.println(fileStatus.getOwner()); System.out.println(fileStatus.getGroup()); System.out.println(fileStatus.getLen()); System.out.println(fileStatus.getModificationTime()); System.out.println(fileStatus.getReplication()); System.out.println(fileStatus.getBlockSize()); System.out.println(fileStatus.getPath().getName()); // 获取块信息 BlockLocation[] blockLocations = fileStatus.getBlockLocations(); System.out.println(Arrays.toString(blockLocations)); } } /** * 判断是文件夹还是文件 * @throws IOException */ @Test public void testFile() throws IOException { FileStatus[] listStatus = fs.listStatus(new Path("/data/input")); for (FileStatus status : listStatus) { if (status.isFile()) { System.out.println("文件:" + status.getPath().getName()); } else { System.out.println("目录:" + status.getPath().getName()); } } } } ``` ### 三、项目目录结构 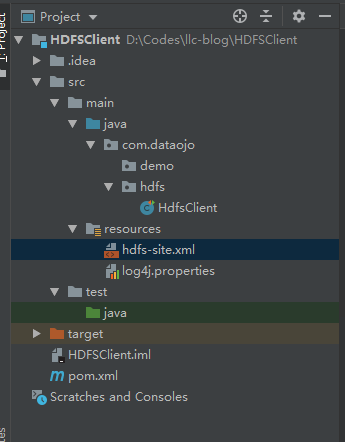
标签:
Hadoop
,
HDFS
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://www.lilinchao.com/archives/1493.html
上一篇
03.HDFS读写流程
下一篇
05.HDFS之NameNode和SecondaryNameNode
取消回复
评论啦~
提交评论
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
标签云
Jquery
Java阻塞队列
Http
随笔
容器深入研究
SpringCloud
Filter
NIO
线程池
Netty
Stream流
Beego
设计模式
Shiro
队列
并发线程
BurpSuite
Tomcat
Hive
MyBatis-Plus
JavaWEB项目搭建
哈希表
Kafka
LeetCode刷题
SpringCloudAlibaba
VUE
Java
微服务
数据结构和算法
正则表达式
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞