李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
Spark和Hadoop比较
Leefs
2021-02-15 AM
1642℃
0条
# 02.Spark和Hadoop比较 ### 一、历史比较 #### Hadoop + 2006 年 1 月,Doug Cutting 加入 Yahoo,领导 Hadoop 的开发 + 2008 年 1 月,Hadoop 成为 Apache 顶级项目 + 2011 年 1.0 正式发布 + 2012 年 3 月稳定版发布 + 2013 年 10 月发布 2.X (Yarn)版本 #### Spark + 2009 年,Spark 诞生于伯克利大学的 AMPLab 实验室 + 2010 年,伯克利大学正式开源了 Spark 项目 + 2013 年 6 月,Spark 成为了 Apache 基金会下的项目 + 2014 年 2 月,Spark 以飞快的速度成为了 Apache 的顶级项目 + 2015 年至今,Spark 变得愈发火爆,大量的国内公司开始重点部署或者使用 Spark ### 二、功能比较 #### Hadoop + Hadoop 是由 java 语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架。 + 作为 Hadoop 分布式文件系统,HDFS 处于 Hadoop 生态圈的最下层,存储着所有的数 据 , 支 持 着 Hadoop 的 所有服 务。它 的 理 论 基 础 源 于 Google 的 TheGoogleFileSystem 这篇论文,它是 GFS 的开源实现。 + MapReduce 是一种编程模型,Hadoop 根据 Google 的 MapReduce 论文将其实现, 作为 Hadoop 的分布式计算模型,是 Hadoop 的核心。基于这个框架,分布式并行 程序的编写变得异常简单。综合了 HDFS 的分布式存储和 MapReduce 的分布式计 算,Hadoop 在处理海量数据时,性能横向扩展变得非常容易。 + HBase 是对 Google 的 Bigtable 的开源实现,但又和 Bigtable 存在许多不同之处。 HBase 是一个基于 HDFS 的分布式数据库,擅长实时地随机读/写超大规模数据集。 它也是 Hadoop 非常重要的组件。 #### Spark + Spark 是一种由 Scala 语言开发的快速、通用、可扩展的大数据分析引擎 + Spark Core 中提供了 Spark 最基础与最核心的功能 + Spark SQL 是 Spark 用来操作结构化数据的组件。通过 Spark SQL,用户可以使用 SQL 或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。 + Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件,提供了丰富的 处理数据流的 API。 Spark 出现的时间相对较晚,并且主要功能主要是用于数据计算, 所以其实 Spark 一直被认为是 Hadoop 框架的升级版。 ### 三、Spark比MapReduce快的原因 **1. Spark 基于内存迭代,而 MapReduce基于磁盘迭代** + MapReduce:中间结果保存到文件,可以提高可靠性,减少内存占用,但是牺 牲了性能。 + 数据在内存中进行交换,速度要快一些,但是可靠性比不过 MapReduce。 **2. DAG 计算模型在迭代计算上比 MR 的更有效率** **有向无环图(DAG):**如果一个有向图无法从某个顶点出发经过若干条边回到该点,则这个图是 一个有向无环图。 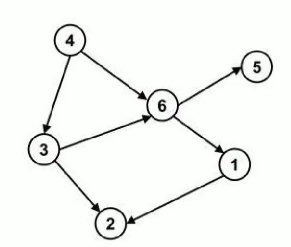 Spark的DAGScheduler相当于一个改进版的MapReduce,如果计算不涉及与其他节点进行数据交换,Spark可以在内存中一次性完成这些操作,也就是中间结果无须落盘,减少了磁盘IO的操作。但是,如果计算过程中涉及数据交换,Spark也是会把shuffle的数据进行落盘。 **一般而言,Spark相比MapReduce在大多数情况下可以减少shuffle次数**。 **3. Hadoop MapReduce采用了多进程模型,而Spark采用了多线程模型** **多进程模型便于细粒度控制每个任务占用的资源,但会消耗较多的启动时间,不适合运行低延迟类型的作业,这是MapReduce广为诟病的原因之一。**而多线程则相反,该模型使得Spark很适合运行低延迟类型的作业。 Spark同节点上的任务以多线程的方式运行在一个JVM进程中,可带来以下好处: (1)任务启动速度快,与之相反的是MapReduce Task进程的慢启动速度,通常需要1s左右; (2)同节点上所有任务运行在一个进程中,有利于共享内存。这非常适合内存密集型任务,尤其对于那些需要加载大量词典的应用程序,可大大节省内存。 (3)同节点上所有任务可运行在一个JVM进程(Executor)中,且Executor所占资源可连续被多批任务使用,不会在运行部分任务后释放掉,这避免了每个任务重复申请资源带来的时间开销,对于任务数目非常多的应用,可大大降低运行时间。与之对比的是MapReduce中的Task:每个Task单独 申请资源,用完后马上释放,不能被其他任务重用,尽管1.0支持JVM重用在一定程度上弥补了该问题,但2.0尚未支持该功能。 本篇的多进程和多线程,指的是同一个节点上多个任务的运行模式。 无论是MapReduce和Spark,整体上看,都是多进程:MapReduce应用程序是由多个独立的Task进程组成的;Spark应用程序的 运行环境是由多个独立的Executor进程构建的临时资源池构成的。 **总结**  ### 四、计算过程对比 **1. Hadoop MapReduce框架** - 从数据源获取数据,经过分析计算后,将结果输出到磁盘的指定位置,当需要该计算结果作为下次计算的数据时,需要从磁盘中进行读取后再进行计算,核心是一次计算, 不适合迭代计算。  **2. Spark框架** - 支持迭代式计算,图形计算 - 中间结果不落盘 *注意:如果计算过程中涉及数据交换,Spark也是会把shuffle的数据进行落盘*  ### 五、总结 经过上面的比较,我们可以看出在绝大多数的数据计算场景中,Spark 确实会比 MapReduce 更有优势。但是 Spark 是基于内存的,所以在实际的生产环境中,由于内存的限制,可能会 由于内存资源不够导致 Job 执行失败,此时,MapReduce 其实是一个更好的选择,所以 Spark 并不能完全替代 MR。
标签:
Spark
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://www.lilinchao.com/archives/1161.html
上一篇
Spark入门介绍
下一篇
windows10 scala安装
取消回复
评论啦~
提交评论
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
标签云
JavaSE
MyBatis-Plus
数学
Livy
Stream流
DataX
Spark Core
gorm
SQL练习题
并发编程
Beego
链表
Tomcat
ajax
BurpSuite
MySQL
CentOS
Filter
机器学习
Hadoop
Thymeleaf
Spark RDD
MyBatis
并发线程
Kafka
哈希表
序列化和反序列化
字符串
持有对象
容器深入研究
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞